들어가며
Rule-based 챗봇의 한계를 개선하기 위해 RAG 기반 챗봇을 개발하게 되었습니다. 이 글에서는 시스템 구조, 챗봇고도화 방법과 챗봇 평가까지의 과정에서 얻은 경험을 공유합니다.
기존 챗봇의 한계
기존 챗봇은 Rule-based 방식으로 운영되었습니다. 미리 정의된 질문-답변 쌍이 저장되어 있고, 사용자가 저장된 질문과 유사한 형태로 질문하도록 유도하는 방식이었습니다.
이 방식에는 몇 가지 한계가 있었습니다.
- 질문 표현이 조금만 달라져도 적절한 답변을 찾지 못함
- 새로운 질문 유형에 대응하려면 수동으로 데이터 추가 필요
- 자연스러운 대화 흐름 구현이 어려움
RAG 기반 챗봇 도입
이러한 한계를 해결하기 위해 RAG(Retrieval-Augmented Generation) 기반의 챗봇을 개발하게 되었습니다.
RAG(Retrieval-Augmented Generation)란?
RAG(Retrieval-Augmented Generation)는 거대 언어 모델(LLM)이 답변을 생성할 때, 외부의 신뢰할 수 있는 데이터베이스에서 관련 정보를 검색(Retrieval)하여, 그 정보를 바탕으로 답변을 생성(Generation)하는 기술입니다.
RAG의 동작 흐름
RAG 시스템은 동작 흐름은 아래와 같습니다.
- 사용자 질문 (Query)
: 사용자가 챗봇에게 질문을 던집니다. - 검색 (Retrieval):
: 질문과 가장 관련된 문서를 미리 구축된 벡터 데이터베이스(Vector DB)에서 찾아냅니다. - 답변 생성 (Generation)
: LLM은 참고 자료를 바탕으로 정확하고 근거 있는 답변을 생성합니다. - 프롬프트 증강 (Augmentation)
: 찾은 문서 내용(Context)을 사용자 질문과 합쳐서 LLM에게 보냅니다. - 최종 응답 (Response)
: 특정 응답 포맷으로 생성된 응답을 사용자에게 반환합니다.
이러한 흐름을 구현하여 사용자의 질문 의도를 파악하고, 관련 문서를 검색한 후 LLM이 자연스러운 답변을 생성합니다. 이를 통해 다양한 표현의 질문에도 유연하게 대응할 수 있게 되었습니다.
시스템 아키텍처
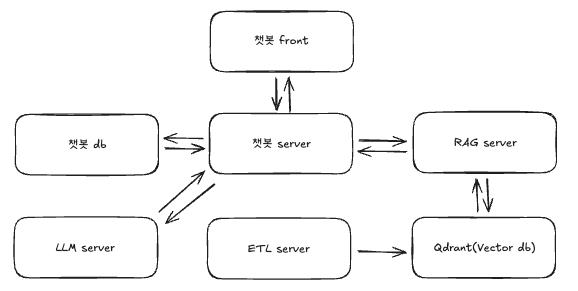
RAG 기반 챗봇 시스템은 다음과 같은 구조로 구성되어 있습니다.
사용자는 챗봇 Front를 통해 질문을 입력하고, 챗봇 Server가 이를 처리합니다. 챗봇 Server는 대화 이력을 챗봇 DB에 저장하고, 질문에 답변하기 위해 RAG Server와 LLM API를 호출합니다.
RAG Server는 Qdrant에서 질문과 관련된 문서를 검색하고, LLM API는 검색된 문서를 바탕으로 답변을 생성합니다.
ETL Server는 문서를 파싱하고 임베딩하여 Vector DB인 Qdrant에 저장하는 역할을 합니다. 스케줄러를 통해 주기적으로 실행되며, 업데이트된 문서를 감지하여 업로드합니다.
챗봇 Server
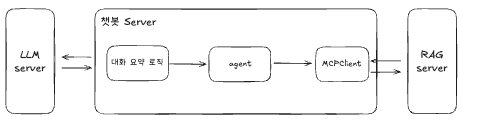
챗봇 Server는 사용자 질문을 처리하는 핵심 컴포넌트입니다.
대화 요약 로직은 이전까지 대화한 원문을 요약하여 컨텍스트를 압축합니다. 대화가 길어지면 전체 내용을 LLM에 전달하기 어려워지므로, 핵심 내용만 요약하여 토큰 사용량을 줄이면서도 맥락을 유지할 수 있도록 합니다.
MCPClient를 이용하여 RAG Server와 상호작용하며 Agent를 통해 문서 검색 tool들을 호출하고 반환된 문서 청크들을 기반으로 LLM 응답을 생성하는 등 최종 응답 생성 흐름을 제어합니다.
RAG Server
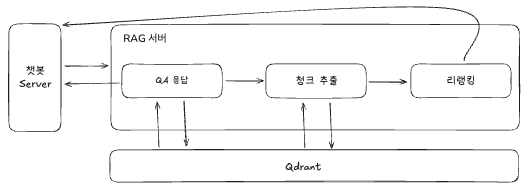
RAG Server는 문서 검색과 관련된 청크 추출을 담당합니다.
1. QA 응답
기존 Rule-based 기반 챗봇의 성능을 그대로 유지하면서 개선하기 위해 응답을 그대로 구현하기 위해서 QA 응답 모듈을 추가했습니다. QA 데이터 기반으로 질문 벡터를 만들고 사용자 질문과의 코사인 유사도가 0.85가 넘으면 반환합니다.
2. 청크 추출
QA 응답을 통해 반환된 결과가 없는 경우, Vector DB(Qdrant)에 저장된 문서 벡터에서 사용자 질문과 유사한 문서들을 최대 70개를 찾아서 반환합니다.
3. 리랭킹
리랭커 모델을 이용하여 추출한 70개의 청크 중 사용자 질문과 가장 관련성 높은 상위 5개의 청크를 선별하고 챗봇 Server로 전달합니다
ETL 서버
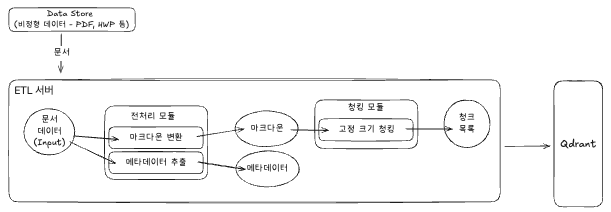
ETL 서버는 비정형 문서 데이터를 RAG 시스템에서 사용할 수 있는 형태로 변환합니다.
PDF, HWP 등의 비정형 문서를 가져와 전처리 모듈에서 처리합니다. 전처리 모듈은 문서를 마크다운으로 변환하고 메타데이터를 추출합니다.
변환된 마크다운과 메타데이터는 청킹 모듈로 전달됩니다. 청킹 모듈은 고정 크기로 문서를 분할하여 최종 청크 목록을 생성합니다. 생성된 청크는 메타데이터와 함께 Qdrant에 저장됩니다.
챗봇 고도화
RAG 시스템은 내부 문서라는 고유한 데이터셋을 다루기 때문에, 외부 벤치마크 점수보다는 내부 시스템 버전 간의 비교가 중요합니다.
<Baseline 설정>
Embedding Model:intfloat/multilingual-e5-large(자체 호스트)
LLM: gemini-2.5-flash
Chunking: 크기 500자, Overlap 100자 (고정크기)
존재하는 모든 내부 문서 기반 Vector DB구축
명확한 비교를 위해 Baseline을 설정하고 데이터 전처리(ETL), 청킹(Chunking), 검색(Retrieval) 세 가지 영역에서 고도화를 진행했습니다.
1. 데이터 전처리(ETL)
가장 먼저 수행한 것은 데이터의 품질을 높이는 것이었습니다. "쓰레기가 들어가면 쓰레기가 나온다(Garbage In, Garbage Out)"는 RAG 시스템에서도 불변의 진리입니다.
① 문서 선별 (20,000 → 8,000 페이지)
Baseline에서는 모든 내부 문서를 DB에 넣었습니다. 하지만 챗봇의 목적과 맞지 않는 문서들은 오히려 검색 정확도를 떨어뜨리는 노이즈가 되었습니다.
- 카테고리 필터링: PDF 중 챗봇 답변에 불필요한 카테고리를 과감히 제거했습니다.
- 분량 필터링: ETL 파이프라인 상에서 내용이 거의 없는 너무 짧은 문서는 자동으로 제외되도록 구현했습니다.
결과적으로 전체 문서는 약 20,000 페이지에서 정예화된 8,000 페이지로 줄어들었고, 벡터 검색의 밀도는 더욱 높아졌습니다.
② 노이즈 제거: 목차와 각주
LLM이 이해하기 어렵거나 검색에 방해가 되는 요소들을 정규표현식(Regex)을 이용해 제거했습니다.
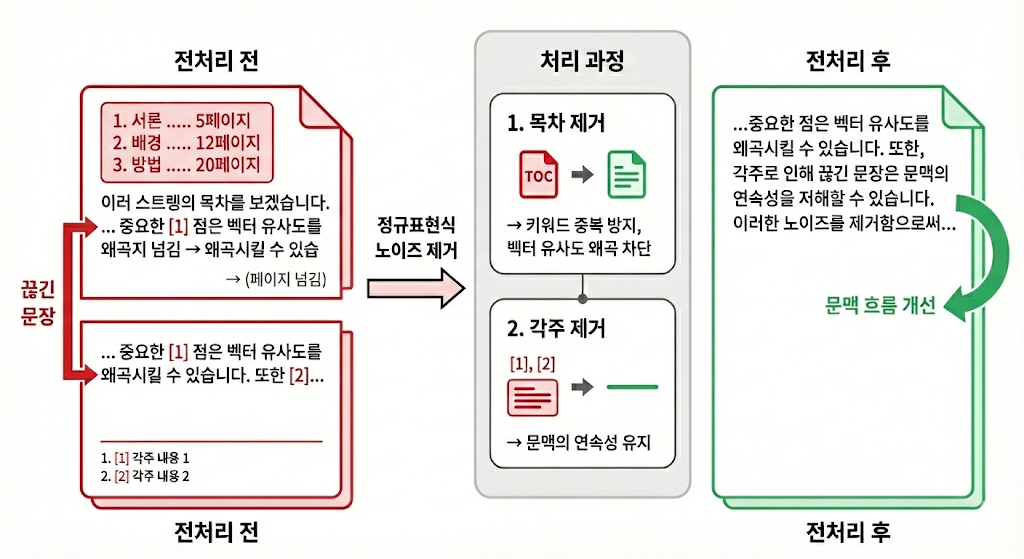
- 목차(Table of Contents) 제거
LLM은 페이지 번호만 보고 실제 위치를 찾아갈 수 없습니다. 오히려 키워드 중복으로 벡터 유사도만 왜곡시키기 때문에, 휴리스틱하게 목차 패턴을 분석하여 최대한 General한 정규표현식으로 제거했습니다. - 각주(Footnote) 제거
각주에 포함된 링크는 LLM이 따라갈 수 없고, 단어 설명은 이미 LLM이 알고 있는 지식인 경우가 많습니다. 무엇보다 치명적인 문제는 문장이 페이지를 넘어갈 때, 중간에 각주가 끼어들면 문맥이 끊겨버린다는 점입니다. 이를 제거함으로써 문장이 매끄럽게 연결되도록 했습니다.
③ PDF 난제 해결: Hybrid Parsing (Text Parsing + Full OCR)
PDF는 본래 '출력'을 위한 포맷이지 '데이터 추출'을 위한 포맷이 아닙니다. 이로 인해 두 가지 큰 문제가 발생했습니다.
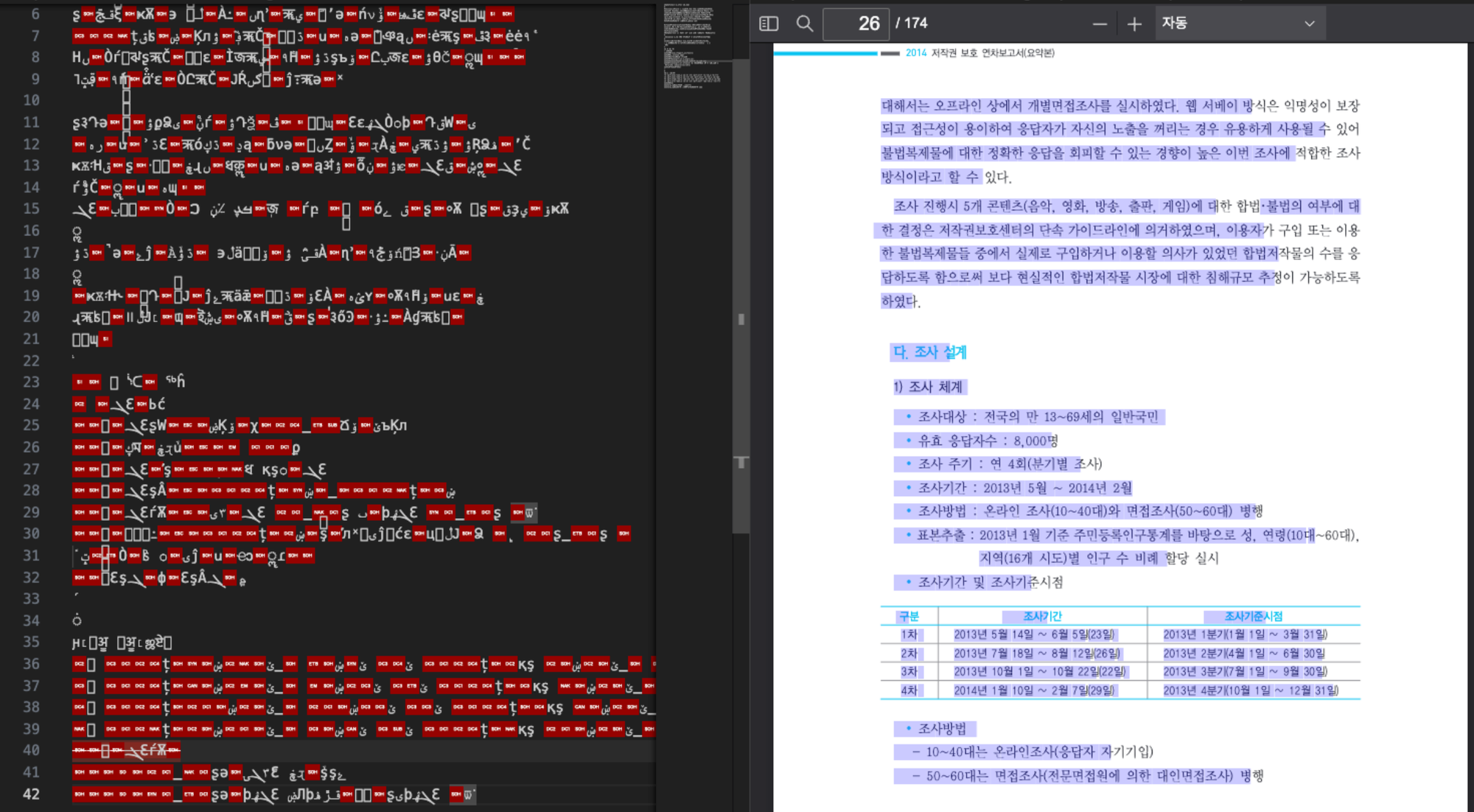
- 폰트 정보 소실
PDF 내부에 폰트 매핑 정보(CMap)가 없으면, 텍스트를 추출했을 때 깨진 특수문자나 외계어처럼 보이는 현상이 발생합니다. - 보안 난독화
보안상의 이유로 텍스트 드래그 및 복사를 막기 위해 내부 데이터를 난독화해 둔 문서들이 존재했습니다.
이를 해결하기 위해 하이브리드 파싱 전략을 도입했습니다.
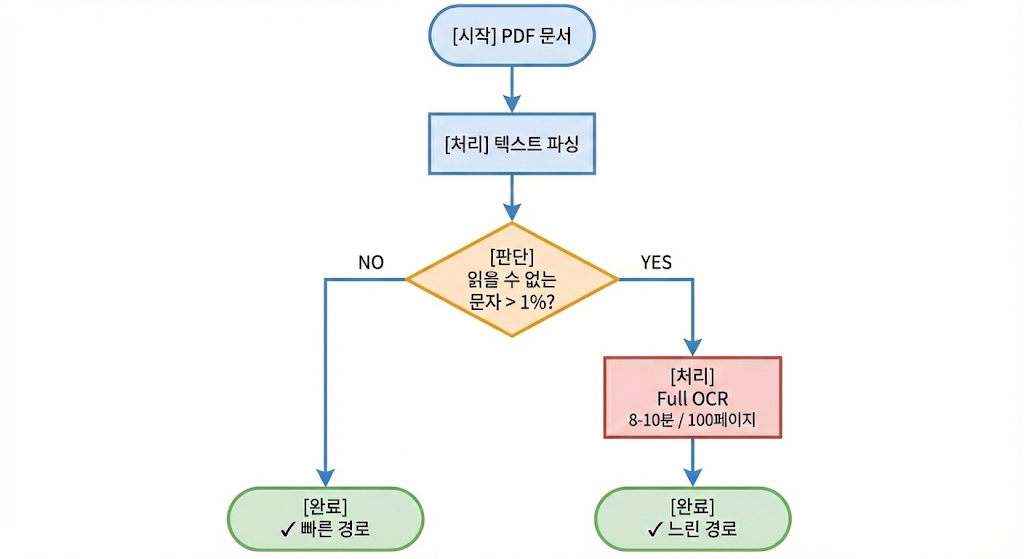
- 1차 시도 (Text Parsing): 먼저 일반적인 라이브러리로 PDF 문서를 전처리합니다.
- 검증: 추출된 텍스트 중 '읽을 수 없는 문자'의 비율이 1%를 초과하는지 검사합니다.
- 2차 시도 (Full OCR): 1%가 넘으면 해당 문서를 '깨진 문서'로 판단하고 문서 전체를 OCR(광학 문자 인식)을 수행하여 문자열로 변환합니다.
Full OCR 수행 시 약 100 페이지의 PDF 문서 전체를 파싱하는데 8 ~ 10분 정도 소요될 정도로 느려서 하이브리드 형태로 구현했습니다.
2. 검색(Retrieval) 고도화: Reranker 도입
Vector DB(ANN 검색)는 빠르지만 완벽하지 않습니다. 단순히 코사인 유사도만으로는 사용자의 미묘한 의도까지 파악하기 어려워, 상위 5개를 뽑았을 때 정답 문서가 6등, 7등에 있어 탈락하는 경우가 발생했습니다.
이를 보완하기 위해 Reranker 모델을 이용하여 2단계 검색(Two-Stage Retrieval) 구조로 변경했습니다.
- Broad Search: Vector DB에서 여유 있게 최대 70개의 후보 청크를 검색합니다.
- Reranking: 별도의 Reranker 모델을 사용하여 70개의 청크와 사용자 질문 간의 관련성을 정밀 채점합니다.
- Final Selection: 점수가 가장 높은 상위 5개를 최종 Context로 LLM에 전달합니다.
챗봇 평가
1. 평가 프레임워크 선정: 왜 RAGAS인가?
앞서 말했듯이 RAG 시스템은 도메인마다 문서의 성격이 다르고, 그에 따른 데이터셋이 천차만별입니다. 따라서 범용적인 벤치마크 점수보다는 내부 데이터를 기반으로 얼마나 잘 검색하고 응답하는지가 중요합니다.
RAGAS는 질문(Query), 응답(Answer), 참고 문맥(Context), 정답(Ground Truth)을 기반으로 다음 지표들을 측정할 수 있어 우리의 니즈에 부합했습니다.
- Faithfulness (생성): 응답이 검색된 문맥(Context)에 충실한가?
- Answer Relevancy (생성): 응답이 질문의 의도와 관련이 있는가?
- Context Precision (검색): 검색된 문맥이 정답과 얼마나 관련 있는가?
- Context Recall (검색): 정답을 도출하는 데 필요한 문맥을 빠짐없이 가져왔는가?
비교 전략: Baseline vs. Improved
RAG 시스템의 특성 상 외부 시스템과의 비교는 무의미하다고 판단하여, 내부 베이스라인 모델을 구축하고 이를 기준으로 개선 모델을 비교 평가하는 방식을 택했습니다.
<Baseline 설정>
Embedding Model:intfloat/multilingual-e5-large(자체 호스트)
LLM: gemini-2.5-flash
Chunking: 크기 500자, Overlap 100자 (고정크기)
존재하는 모든 내부 문서 기반 Vector DB구축
2. 평가 데이터셋 구축
정확한 평가를 위해 데이터셋을 목적에 맞게 두 가지로 나누어 구축했습니다.
① RAG 평가 데이터셋 (2,259개)
PDF 문서를 Markdown으로 전처리한 후, RAGAS의 데이터셋 생성 유틸리티 함수를 이용하여 LLM 기반으로 Query-Ground Truth 쌍 총 2,259개의 테스트 데이터셋을 생성했습니다.
문서의 길이별로 생성할 데이터셋의 개수를 다르게 하여 중복되는 질문이 생성되는 경우를 최대한 줄였습니다.
② QA 평가 데이터셋 (1,910개)
기존 QA 데이터 200개를 기반으로, LLM을 활용해 하나의 질문당 의미는 같지만 문장이 다른 10개의 변형 데이터를 생성(Augmentation)하여 총 1,910개의 테스트 데이터셋를 만들었습니다.
3. 평가 방법
- QA 평가: 정답률(Accuracy) 기반의 단순 비교.
- 구축된 테스트 데이터셋을 기반으로 QA 모듈로의 요청을 보내고 응답 데이터의 정답 여부를 이용해서 Accuracy를 계산해 비교합니다.
- 챗봇 시스템 평가: 최종 단계에서만 전체 파이프라인을 구동하여 모든 지표 측정.
- 구축된 테스트 데이터셋을 기반으로 Faithfulness, Answer Relevancy, Context Precision, Context Recall 총 4개의 평가 지표 각각의 평균을 계산하고 Overall 평균 값을 이용하여 비교합니다.
4. 평가 결과
평가 결과, QA와 RAG 부문 모두에서 괄목할 만한 성과를 거두었습니다.
① QA 시스템 정답률
기존 챗봇 대비 약 3배 가까운 성능 개선을 확인했습니다. 다양한 문장 변형에도 강건하게 답변할 수 있게 되었습니다.
| 구분 | 정답 수 / 전체 | 정답률 |
| 기존 챗봇 | 667 / 1910 | 34.9% |
| 개선된 챗봇 | 1825 / 1910 | 95.55% |
② RAG 시스템 종합 점수 (RAGAS Score)
baseline(단순 청킹 및 임베딩) 대비 전체 평가지표 평균(Overall)이 약 2배 상승했습니다.
| 평가 지표 (Metric) | Baseline | 개선 후 | 증감 |
| Faithfulness (생성) | 0.4565 | 0.7518 | ▲ 0.2953 |
| Answer Relevancy (생성) | 0.6307 | 0.8904 | ▲ 0.2597 |
| Context Precision (검색) | 0.3194 | 0.8084 | ▲ 0.4890 |
| Context Recall (검색) | 0.3233 | 0.8662 | ▲ 0.5429 |
| Overall Mean (평균) | 0.4325 | 0.8292 | ▲ 0.3967 |
특히, 검색 품질을 나타내는 Context Precision과 Context Recall이 0.3점대에서 0.8점대로 대폭 상승한 점이 눈에 띕니다. 이는 검색 시스템이 더 정확한 문서를 빠짐없이 찾아내게 되었고, 그 결과 생성된 답변의 신뢰도(Faithfulness)와 관련성(Answer Relevancy)도 함께 향상되었음을 의미합니다.
마치며
RAG 기반 챗봇 시스템 구축 및 평가를 통해서 배운 점을 정리합니다.
데이터 품질의 중요성
이 과정에서 얻은 가장 큰 수확은 "RAG 시스템의 성능은 결국 데이터의 품질이 결정한다"는 사실이었습니다. 단순히 고성능의 LLM이나 복잡한 검색 알고리즘을 도입하는 것보다, 문서를 정교하게 전처리(ETL)하고 노이즈를 제거하며, 우리 도메인에 맞는 최적의 청킹 전략을 찾는 과정이 성능 향상에 훨씬 결정적인 역할을 했습니다.