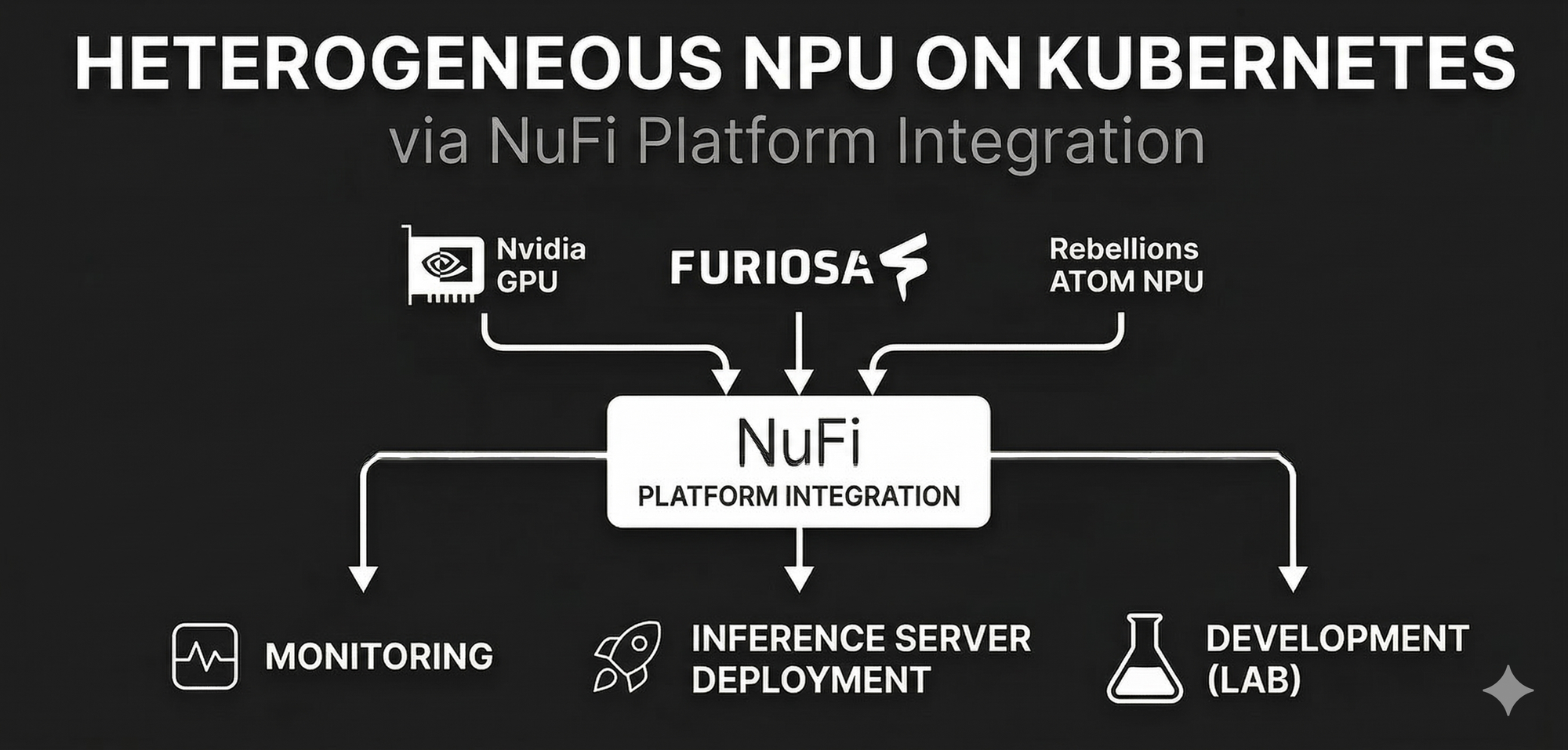
1. 도입: AI 하드웨어 관리의 복잡성을 풀다
LLM(대규모 언어 모델) 서비스가 고도화되면서, 막대한 GPU 도입 비용과 전력 소모를 해결하기 위해 NPU(신경망 처리 장치) 도입을 고려하는 조직이 늘고 있습니다. 하지만 새로운 하드웨어를 Kubernetes 환경에 추가하는 것은 간단하지 않습니다. 디바이스마다 다른 드라이버 설치, 리소스 등록 방식, 모니터링 메트릭 체계가 제각각이라 인프라 관리의 복잡성이 하드웨어 종류에 비례해 늘어납니다.
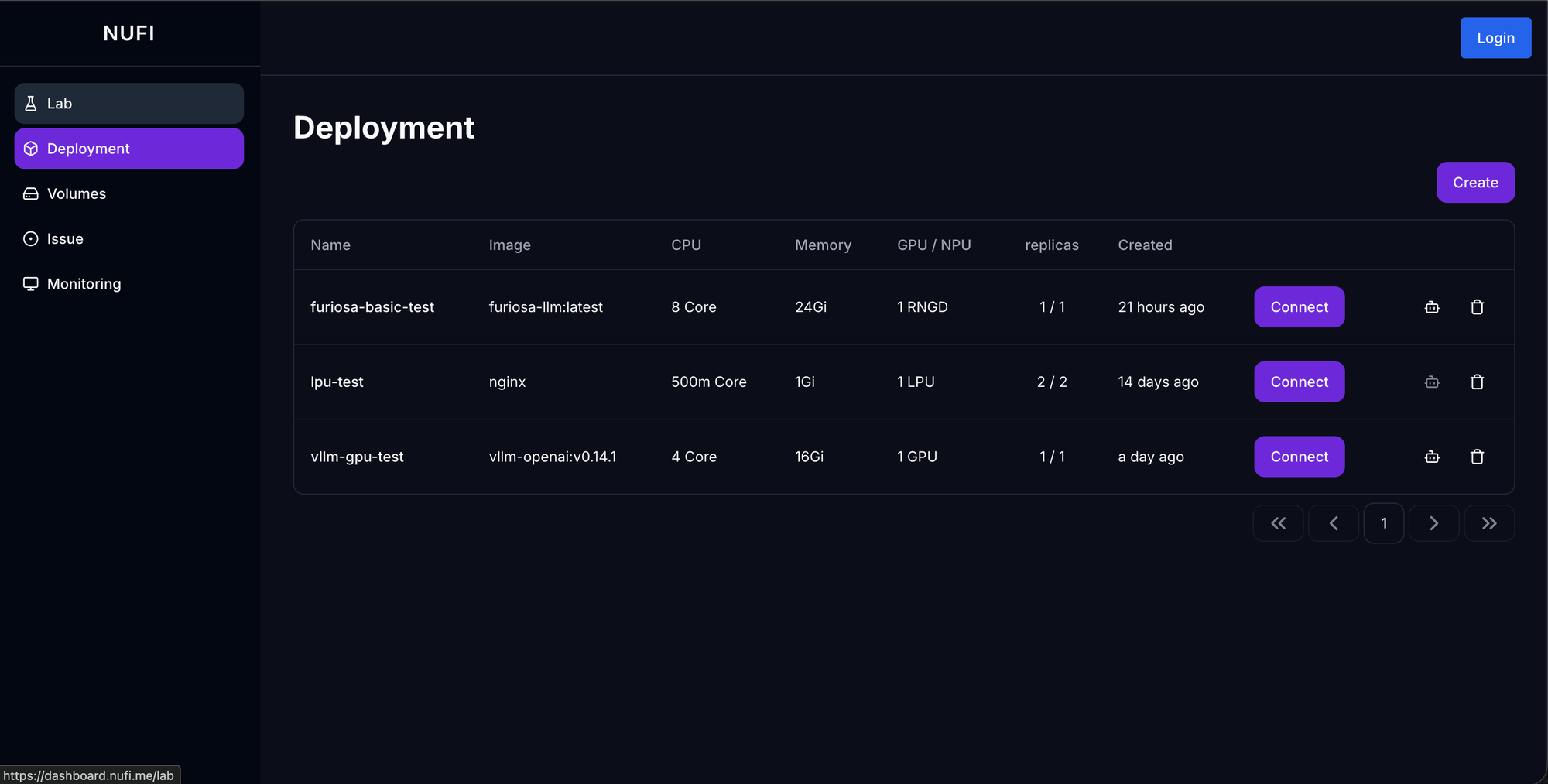
저희 팀은 이 문제를 해결하기 위해 NuFi라는 K8s 기반 AI 모델 서빙 플랫폼을 개발하고 있습니다. GPU와 다양한 NPU를 포함한 이기종 가속기를 일관된 인터페이스로 K8s에 배포하고 관리할 수 있도록 설계했으며, 사용자는 하드웨어 차이를 의식하지 않고 모델 서빙과 개발 환경을 운영할 수 있습니다.

이번 글에서는 FuriosaAI에서 개발한 LLM 추론 특화 NPU인 Furiosa Renegade(RNGD) 를 NuFi에 통합한 실무 과정을 공유합니다. 해당 칩의 상세 스펙은 Furiosa 공식 문서에서 확인할 수 있습니다. FuriosaAI로부터 카드를 한 장 제공받아, 사내 K8s 클러스터에 직접 통합하고 운영 효율성을 검증한 과정과, GPU(RTX 3090) 대비 벤치마크 결과를 함께 다룹니다.
2. K8s 생태계와 NuFi의 유연한 결합: 최소한의 작업으로 끝내는 하드웨어 추가
NuFi에 새로운 디바이스를 추가할 때 핵심은, Kubernetes 표준 인터페이스를 활용하면서도 플랫폼 코어 로직의 변경 없이 통합이 완료된다는 점입니다.
Kubernetes 표준 인터페이스 호환
RNGD를 K8s가 기본 자원으로 인식하도록 하는 과정은 Kubernetes 생태계의 표준을 그대로 따릅니다. Furiosa에서 제공하는 Feature Discovery가 노드에 장착된 NPU를 자동 감지하여 라벨을 부여하고, Device Plugin이 NPU를 K8s 스케줄링 가능한 리소스(furiosa.ai/rngd)로 등록합니다.

두 컴포넌트가 정상 동작하면, 노드의 Allocatable 리소스에 furiosa.ai/rngd가 나타나고, Pod 스펙에서 바로 할당할 수 있습니다.
$ kubectl describe node <node-name>
Allocatable:
cpu: 10
memory: 100Gi
furiosa.ai/rngd: 1 # RNGD 1장 인식
기존에 NVIDIA GPU나 다른 NPU를 통합했던 경험이 있다면 동일한 패턴으로 진행할 수 있어, 새로운 하드웨어 추가에 드는 학습 비용이 최소화됩니다.
플랫폼 통합의 유연성: 코어 로직 유지
저희가 NuFi를 설계할 때 중요하게 생각한 원칙 중 하나는 새로운 디바이스 추가 시 플랫폼 코어 로직을 수정하지 않는 것입니다. NuFi API Server는 DeviceFetcher라는 인터페이스를 통해 다양한 디바이스의 메트릭을 통합 조회합니다. RNGD를 추가할 때도 이 인터페이스를 구현한 Fetcher 하나만 작성하면 됩니다.
type RngdFetcher struct{}
func (f *RngdFetcher) DeviceInfo() DeviceInfo {
return DeviceInfo{
Key: "rngd", Label: "RNGD", Vendor: "FuriosaAI",
MemLabel: "MEM", ResourceKey: "furiosa.ai/rngd",
}
}
func (f *RngdFetcher) DeviceQueries() DeviceQuerySet {
return DeviceQuerySet{
Utilization: `avg by (hostname, device, ...) (furiosa_npu_core_utilization)`,
Temperature: `avg by (hostname, device, ...) (furiosa_npu_hw_temperature{label="peak"})`,
Power: `avg by (hostname, device, ...) (furiosa_npu_hw_power{label="rms"})`,
Memory: `avg by (hostname, device, ...) (furiosa_npu_dram_usage / furiosa_npu_dram_total * 100)`,
}
}
위 코드에서 보듯, DeviceQueries() 메서드 내에 Prometheus PromQL 쿼리 몇 줄만 정의해주면 끝입니다. 이후 DeviceRegistry에 이 RngdFetcher를 등록하기만 하면, API Server가 Prometheus 쿼리로 RNGD 존재 여부를 자동 감지하고(furiosa_npu_alive 메트릭) 메트릭 수집을 시작합니다. 복잡한 플랫폼 수정 없이, Fetcher 하나와 Dashboard 옵션 추가만으로 통합이 완료되는 구조입니다.
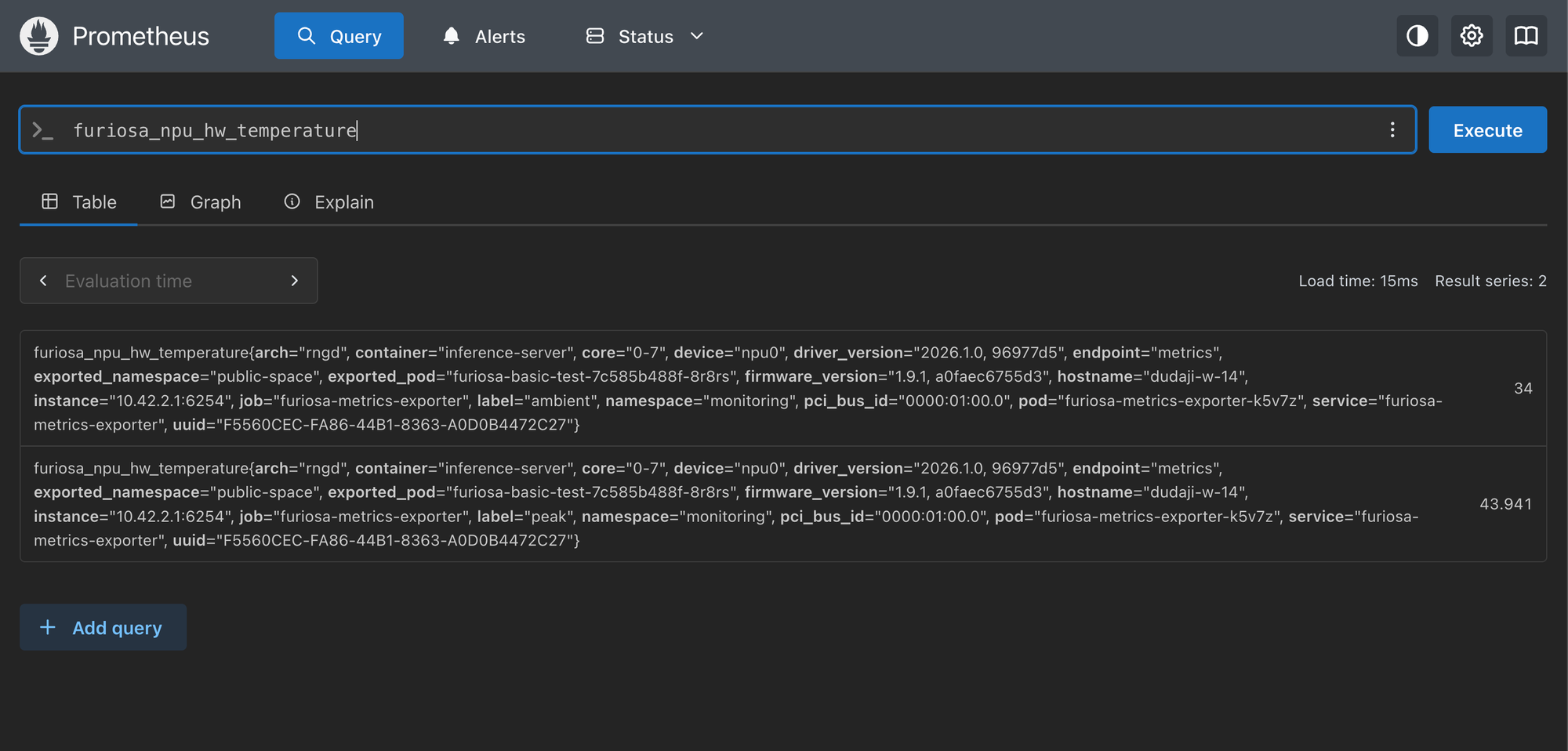
통합 모니터링
디바이스가 인식되면, Furiosa Metrics Exporter가 Prometheus 메트릭을 수집합니다. NuFi는 이 메트릭을 Fetcher를 통해 변환하여, 대시보드 단일 화면에서 NPU의 핵심 지표(사용률, 온도, 전력, 메모리)를 GPU와 동일한 방식으로 보여줍니다. 디바이스 종류가 늘어나도 별도의 모니터링 도구를 익힐 필요 없이, 하나의 화면에서 모든 가속기의 상태를 파악할 수 있도록 했습니다.
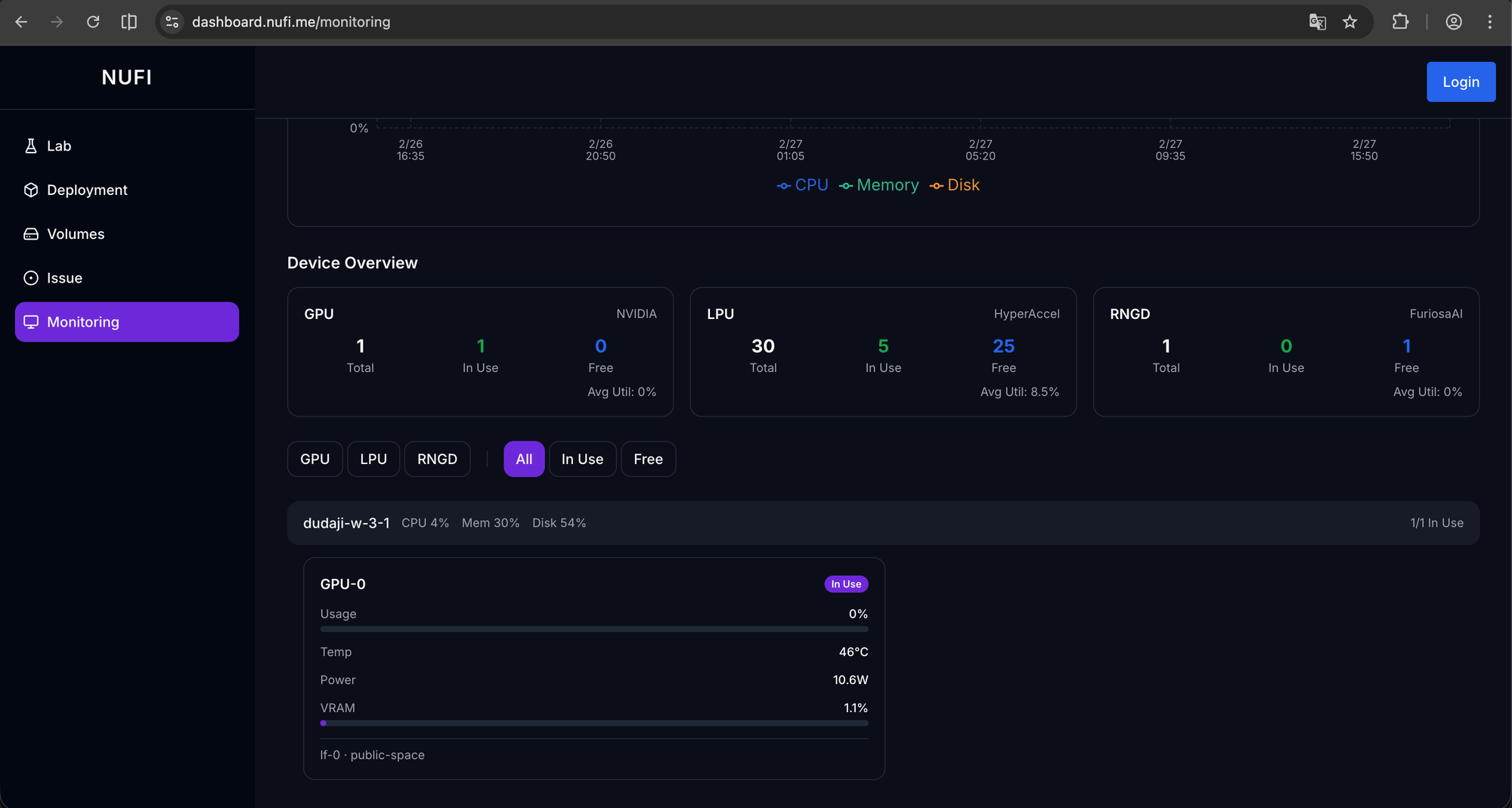
기존 추론 파이프라인 재사용
실제 추론 서버는 Furiosa에서 제공하는 furiosa-llm으로 모델을 서빙합니다. furiosa-llm이 OpenAI 호환 API를 제공하므로, NuFi의 기존 서빙 아키텍처(nufi-proxy → 추론 서버)를 그대로 활용할 수 있습니다. 새로운 하드웨어를 추가했지만 서빙 파이프라인은 바꿀 필요가 없는 것입니다.
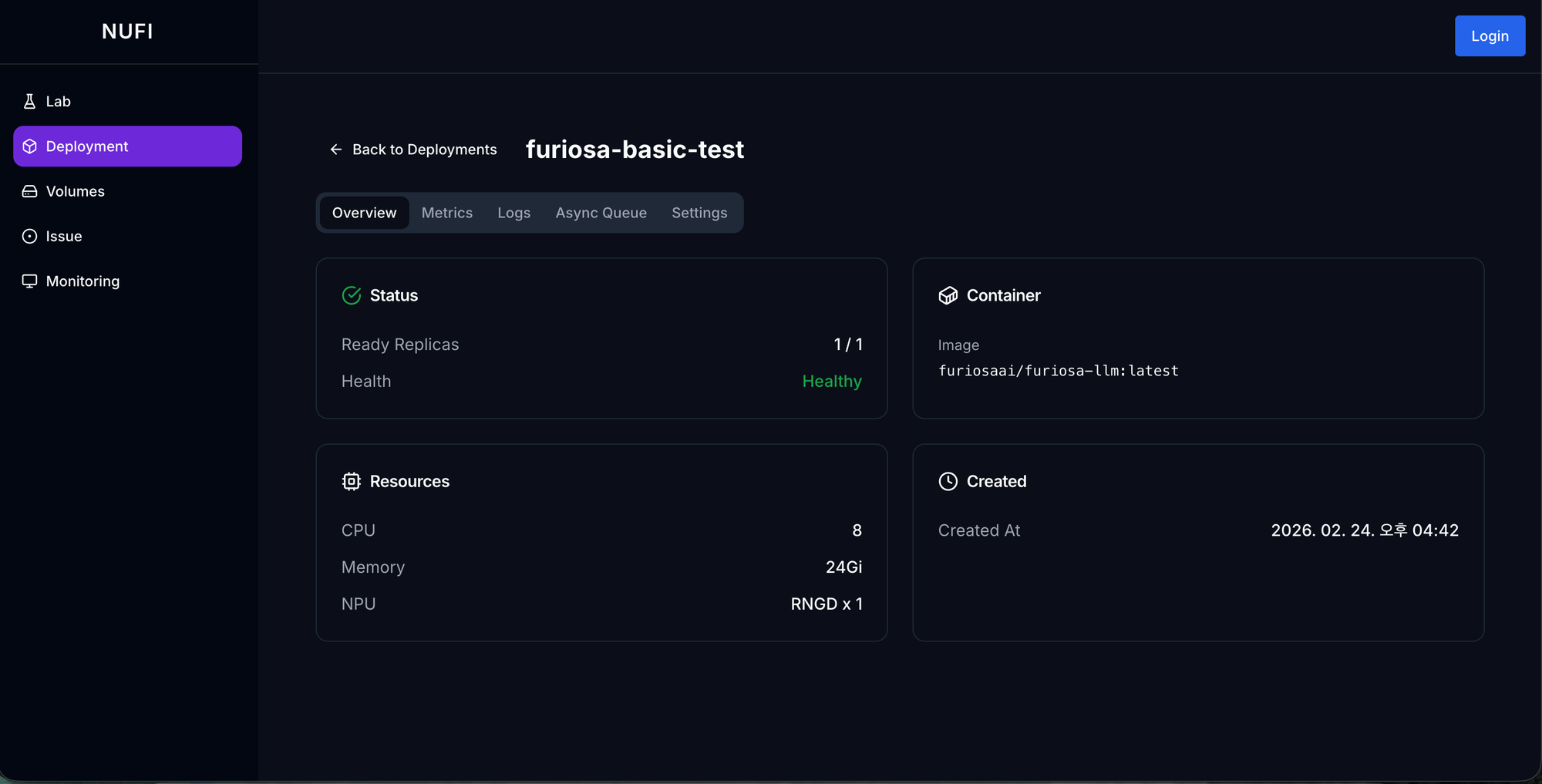
3. NuFi Lab: 인프라 셋업 없이 즉시 시작하는 NPU 실험 환경
새로운 하드웨어를 도입하면, 개발자들이 가장 먼저 마주하는 허들은 개발 환경 구성입니다. 드라이버 설치, SDK 세팅, 디바이스 마운트 확인 등 모델을 한 번 돌려보기 전에 거쳐야 할 단계가 적지 않습니다.
NuFi의 Lab 기능은 이 과정을 최소화합니다. 웹 대시보드에서 디바이스로 FuriosaAI RNGD를 선택하고, Furiosa SDK가 포함된 노트북 이미지를 지정하면, RNGD가 마운트되고 SDK가 세팅된 Jupyter Notebook 환경이 자동으로 생성됩니다.
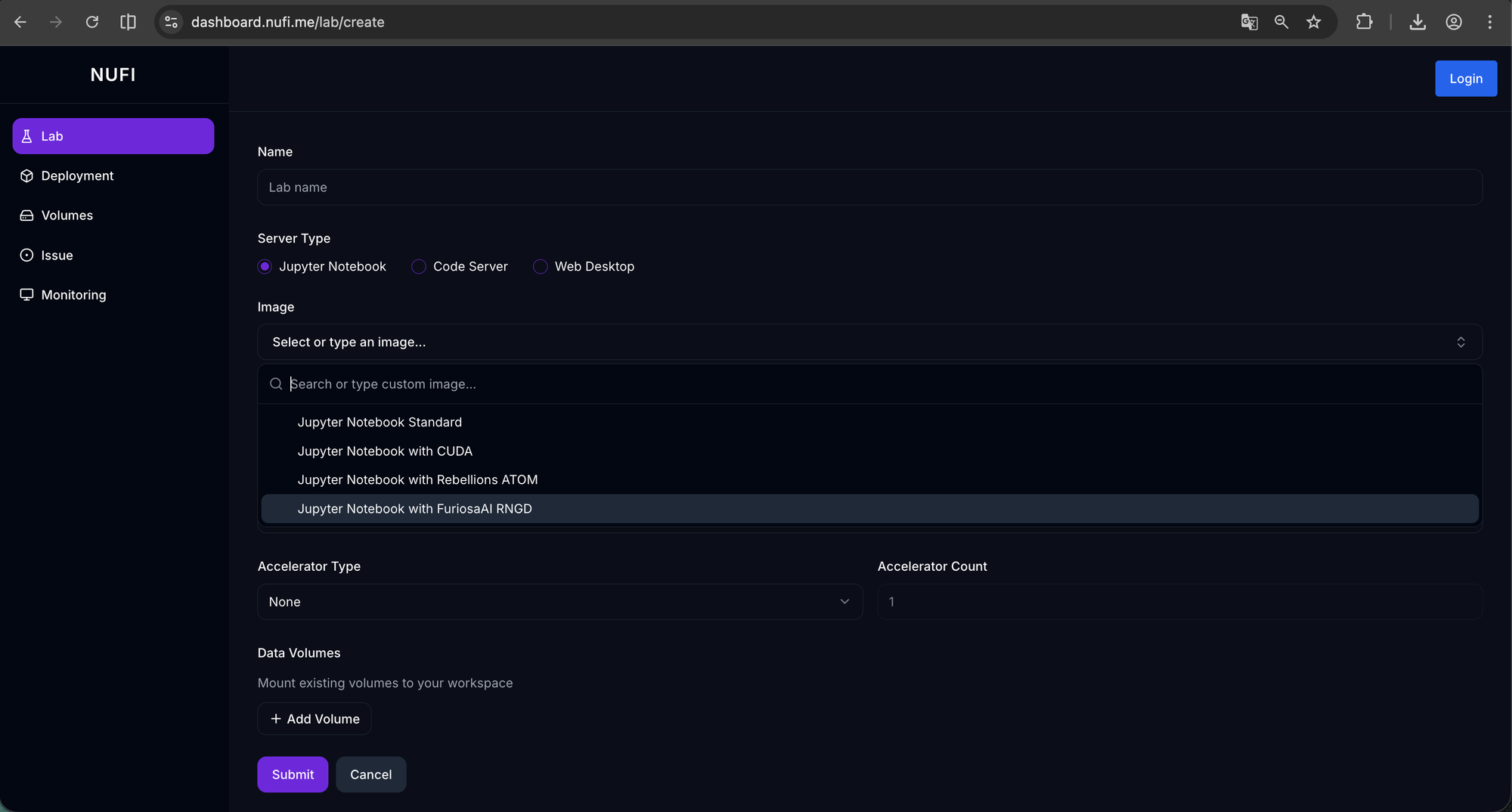
Lab이 생성되면 브라우저에서 바로 Jupyter Notebook에 접속하여, 별도의 환경 설정 없이 바로 Furiosa SDK를 사용할 수 있습니다.
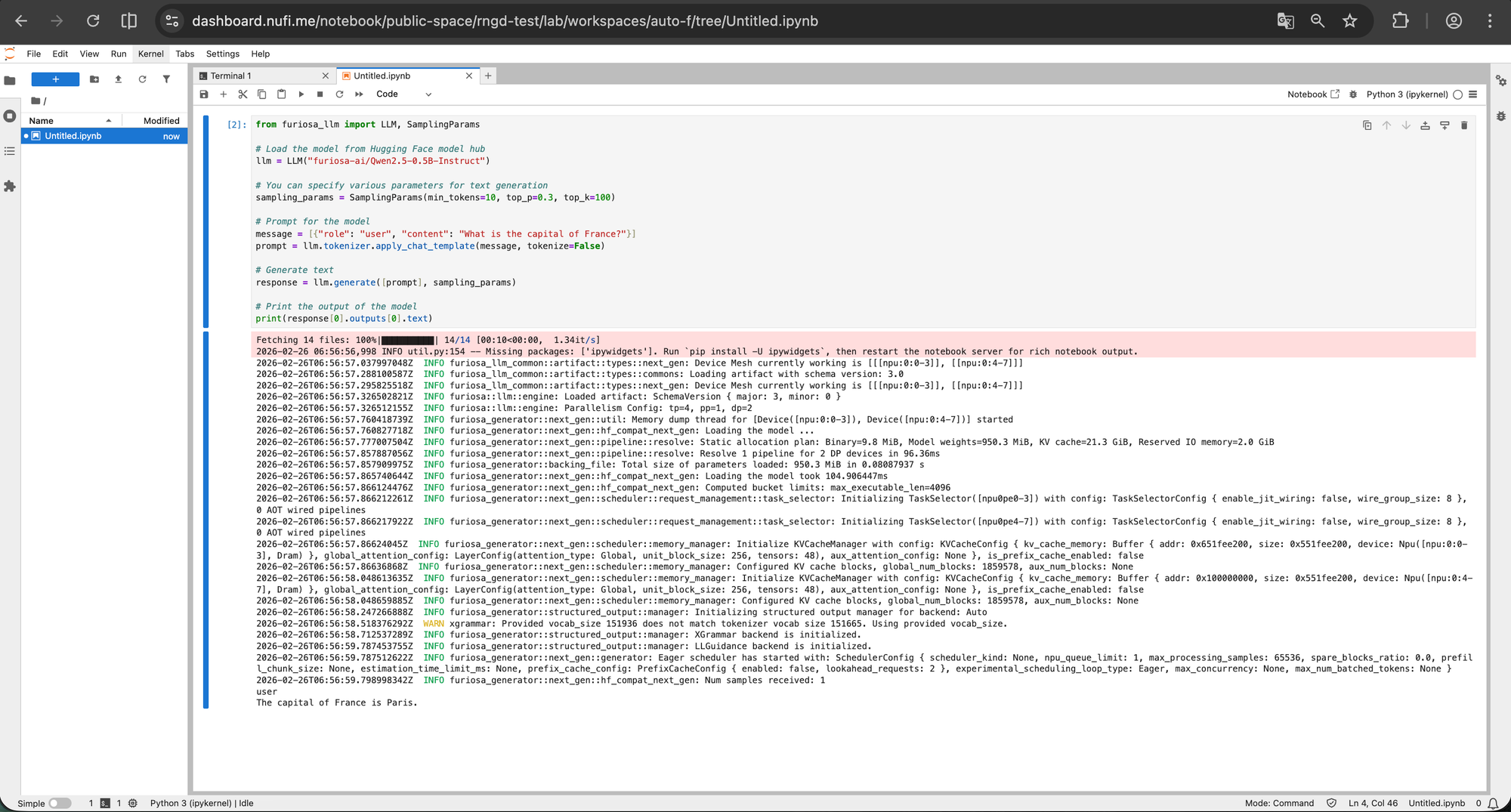
Notebook에서 RNGD로 추론 예시 코드 보기
from furiosa_llm import LLM, SamplingParams
# Load the model from Hugging Face model hub
llm = LLM("furiosa-ai/Qwen2.5-0.5B-Instruct")
# You can specify various parameters for text generation
sampling_params = SamplingParams(min_tokens=10, top_p=0.3, top_k=100)
# Prompt for the model
message = [{"role": "user", "content": "What is the capital of France?"}]
prompt = llm.tokenizer.apply_chat_template(message, tokenize=False)
# Generate text
response = llm.generate([prompt], sampling_params)
# Print the output of the model
print(response[0].outputs[0].text)
인프라 지식 없이도 웹 브라우저만으로 RNGD 위에서 LLM을 실험할 수 있습니다. 모델 서빙 배포 전에 프롬프트를 테스트하거나, 새로운 모델을 빠르게 검증하는 용도로 활용할 수 있어, NPU 도입 초기의 탐색 비용을 크게 줄여줍니다.
4. NuFi 환경에서 검증한 RNGD 성능: vs RTX 3090
RNGD가 NuFi에 정상적으로 통합된 것을 확인한 후, 동일한 K8s 클러스터 내에서 NVIDIA RTX 3090과의 성능을 비교해 보았습니다. NuFi를 통해 비교 대상 디바이스들을 동일한 환경에서 손쉽게 배포하고 통제할 수 있어, 공정한 벤치마크 환경을 구성하기 수월했습니다.
비교 대상에 대해: RTX 3090은 소비자용 GPU이고, RNGD는 데이터센터용 NPU이므로 제품 등급이 다릅니다. A100이나 H100 같은 데이터센터용 GPU와의 비교가 더 적절할 수 있지만, 이번 테스트에서는 클러스터에 당장 사용 가능한 GPU가 RTX 3090뿐이었기에 이를 기준으로 삼았습니다. 따라서 절대적인 GPU vs NPU 성능 비교보다는, 동일 클러스터 내에서 기존 GPU를 NPU로 대체했을 때 어떤 변화가 있는지를 확인하는 데 초점을 맞추고 있습니다.
4-1. 벤치마크 환경
| 항목 | RNGD | RTX 3090 |
|---|---|---|
| 모델 | furiosa-ai/Llama-3.1-8B-Instruct |
meta-llama/Llama-3.1-8B-Instruct |
| 서빙 프레임워크 | furiosa-llm | vLLM |
| CPU | 10 core | 10 core |
| Memory | 24Gi | 24Gi |
| max-model-len | - | 8192 |
RNGD는 FuriosaAI에서 사전 컴파일한 모델(
furiosa-ai/Llama-3.1-8B-Instruct)을 사용합니다. 원본 모델은 동일한meta-llama/Llama-3.1-8B-Instruct입니다.
벤치마크 조건:
- Input: 1024 토큰 (고정 길이, 동일 프롬프트)
- Output: 1024 토큰 (
ignore_eos=True) - 동시 요청 수: 1, 2, 4, 8, 16, 32, 64로 단계적 증가
- 벤치마크 도구: vLLM bench 기반
데이터셋 참고:
--dataset-name fixed옵션은 모든 요청에 동일한 고정 길이 프롬프트를 사용합니다. 기본 성능 비교(Prefix Caching OFF)에서는 결과에 영향이 없지만, 후반부의 Prefix Caching 분석에서는 이 특성이 중요한 의미를 가집니다.
4-2. 벤치마크 결과
동시 요청 수를 1부터 64까지 늘려가며 RNGD와 RTX 3090 각각에 대해 Prefix Caching ON/OFF, 총 4가지 조합으로 처리량, 레이턴시, 전력 효율을 측정했습니다.
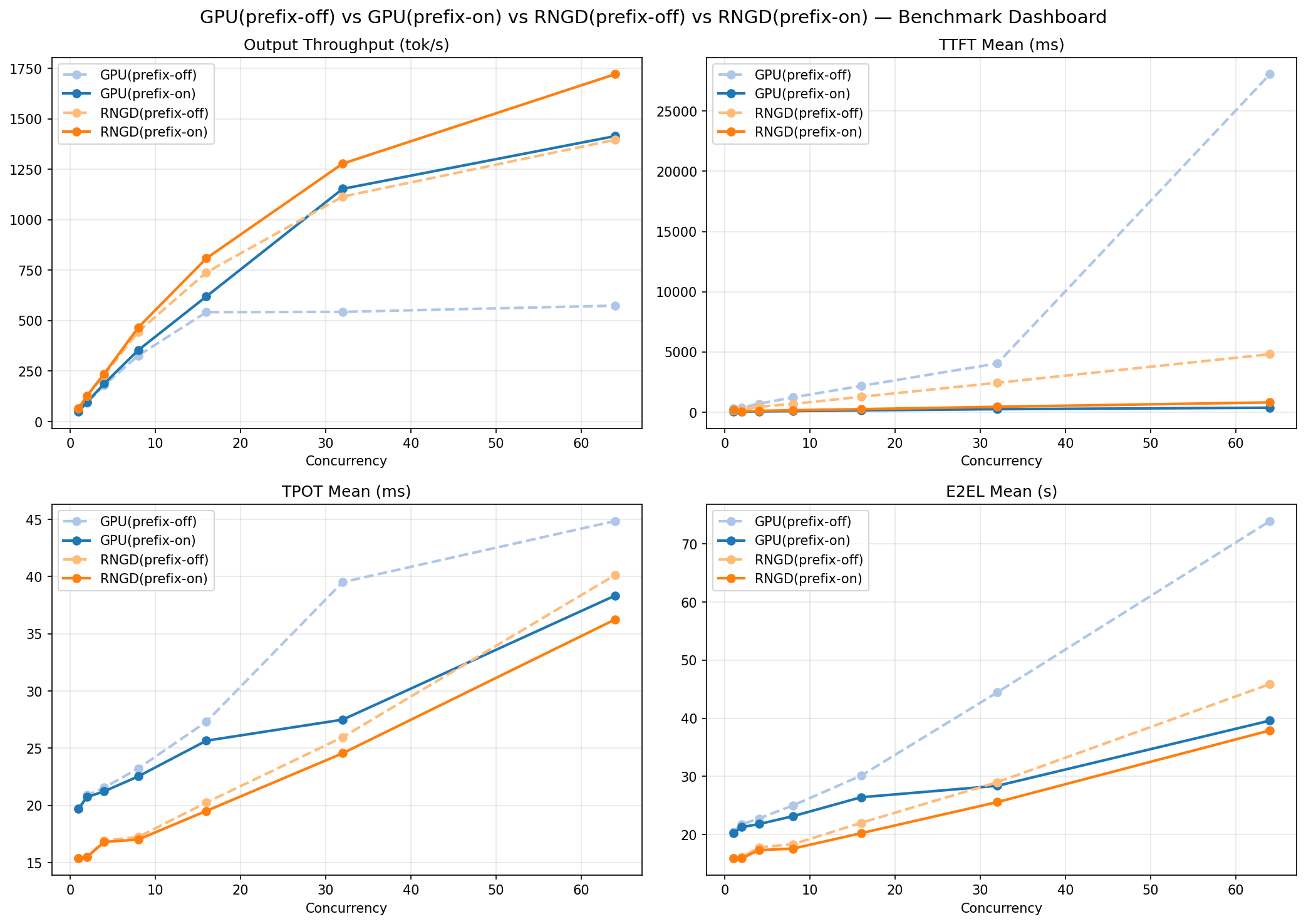
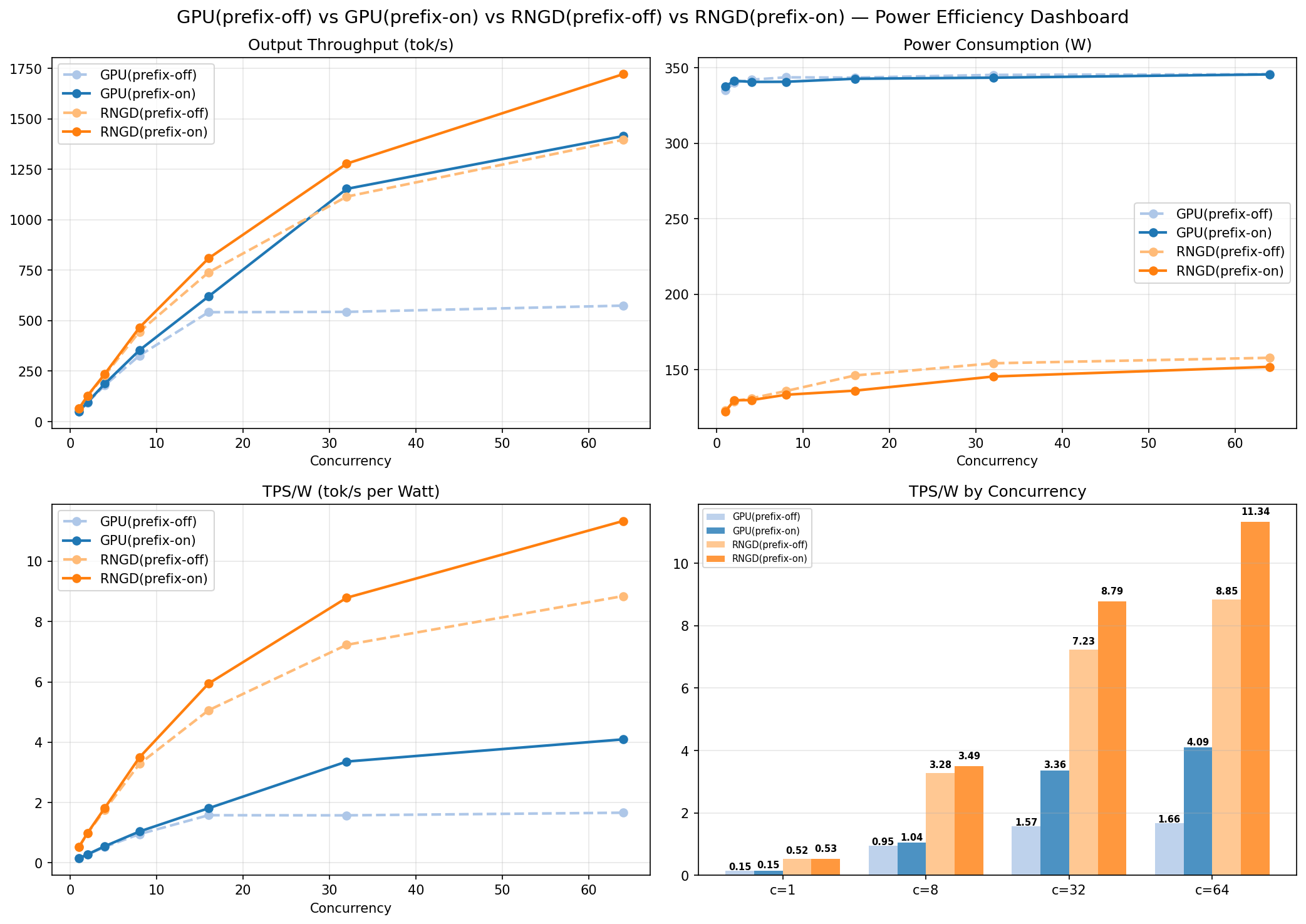
Prefix Caching이란? 여러 요청이 동일한 접두사(예: System Prompt)를 공유할 때, 해당 부분의 KV Cache를 재활용하여 중복 연산을 제거하는 최적화 기법입니다. Furiosa SDK 2026.1.0 릴리즈에서 Branch-compressed radix tree 기반으로 새로 추가되었으며, SGLang의 RadixAttention과 유사한 접근입니다. 이번 벤치마크는 모든 요청에 동일한 1024 토큰 프롬프트를 사용하므로 Cache Hit Rate가 거의 100%에 가까운 이상적인 조건입니다.
수치 데이터 상세 (표 펼치기)
Prefix Caching OFF 기본 비교 (각 셀: RNGD / RTX 3090)
| 동시 요청 수 | Output Throughput (tok/s) | TTFT mean (ms) | TPOT mean (ms) | E2E Latency mean (s) | 전력 효율 (tok/s/W) |
|---|---|---|---|---|---|
| 1 | 64.4 / 50.0 | 166 / 322 | 15.4 / 19.7 | 15.9 / 20.5 | 0.52 / 0.15 |
| 8 | 445.5 / 327.1 | 688 / 1,233 | 17.2 / 23.2 | 18.3 / 25.0 | 3.28 / 0.95 |
| 16 | 739.4 / 542.3 | 1,283 / 2,183 | 20.3 / 27.3 | 22.0 / 30.1 | 5.06 / 1.58 |
| 32 | 1,115.1 / 543.9 | 2,444 / 4,049 | 26.0 / 39.5 | 29.0 / 44.5 | 7.23 / 1.57 |
| 64 | 1,396.6 / 574.8 | 4,814 / 28,063 | 40.1 / 44.9 | 45.9 / 74.0 | 8.85 / 1.66 |
전력: RNGD는 122~158W(TDP 150W), RTX 3090은 335~346W(TDP 350W)를 소비했습니다.
Prefix Caching ON 시 개선 효과
| 동시 요청 수 | RNGD TTFT 개선 | RNGD Throughput 개선 | RTX 3090 Throughput 개선 |
|---|---|---|---|
| 1 | - (오버헤드) | - | +1.4% |
| 8 | 75.9%↓ | +4.6% | +8.2% |
| 32 | 81.6%↓ | +14.7% | +112.1% |
| 64 | 83.1%↓ | +23.3% | +146.2% |
핵심 관찰:
- Throughput: Prefix Caching OFF 기준, RNGD가 동시 요청 1개에서 1.3배 → 64개에서 2.4배 우위. RTX 3090은 c=16 이후 약 540 tok/s에서 포화되는 반면, RNGD는 64개까지 꾸준히 스케일링.
- TTFT: c=64에서 RNGD 4.8초 vs RTX 3090 28.1초로 5.8배 차이. RTX 3090의 p99 TTFT는 약 88초로 실서비스에서 사실상 사용 불가.
- 전력 효율: RNGD가 3.2~5.3배 높은 전성비. GPU 대비 절반 이하의 전력으로 더 높은 처리량 달성.
- Prefix Caching: RNGD에서 c=64 기준 TTFT 83% 감소, Throughput 23% 증가. 전력 효율은 11.34 tok/s/W로 같은 조건 RTX 3090(4.09 tok/s/W) 대비 2.8배. RTX 3090도 Prefix Caching으로 c=64 기준 +146% 처리량 증가를 보였지만(c=16 이후 포화 해소), Throughput·TPOT·전력 효율에서는 여전히 RNGD가 우위.
4-3. 결과 요약
| 지표 | RNGD 우위 | 핵심 관찰 |
|---|---|---|
| Throughput | 1.3~2.4x | 동시 요청 증가 시 격차 확대. GPU는 c=16에서 포화 |
| TTFT | 1.9~5.8x | GPU는 고부하에서 급격히 악화 (c=64에서 28초) |
| TPOT | 1.1~1.5x | 전 구간에서 안정적으로 빠른 토큰 생성 |
| 전력 효율 | 3.2~5.3x | 동일 처리량에 필요한 전력이 수 배 적음 |
| + Prefix Caching | TTFT 83%↓, Throughput 23%↑ | 캐시 히트 100% 조건 상한선 |
RNGD는 단순히 "빠르다"를 넘어, 압도적인 전성비로 스케일링됩니다. RTX 3090 대비 더 높은 처리량을 절반도 안 되는 전력으로 달성했으며, 동시 요청이 많은 실서비스 환경에서도 안정적으로 스케일링되었습니다. Prefix Caching까지 활용하면 전력 효율은 최대 6.8배(c=32 기준)까지 차이가 벌어집니다.
5. 마무리: NPU 도입의 진입 장벽을 낮추는 NuFi
이번 Furiosa RNGD 통합을 통해, 저희가 NuFi를 설계하면서 중요하게 생각했던 원칙들이 실제로 잘 동작한다는 것을 확인할 수 있었습니다.
- 최소한의 통합 비용:
DeviceFetcher인터페이스 하나만 구현하면 코어 로직 변경 없이 새로운 디바이스가 연동됩니다. 이번에도 Fetcher 하나와 Dashboard 옵션 추가만으로 통합이 완료되었습니다. - 즉각적인 Lab 환경: 웹 대시보드에서 클릭 몇 번이면 NPU가 마운트된 Jupyter Notebook이 생성됩니다. 개발자들이 인프라 셋업 없이 바로 모델을 실험할 수 있도록 만든 기능인데, RNGD에서도 의도대로 동작했습니다.
- 통합 모니터링과 서빙: 디바이스 종류가 늘어나도 하나의 대시보드에서 모니터링하고, 동일한 추론 파이프라인으로 서빙할 수 있습니다.
저희는 NuFi를 특정 하드웨어 벤더에 종속되지 않는 플랫폼으로 만들어가고 있습니다. 조직의 예산과 서비스 요구사항에 맞춰 최적의 AI 가속기(GPU/NPU)를 유연하게 선택하고, 즉시 프로덕션 수준으로 운영할 수 있는 환경을 목표로 합니다. 국내 NPU 생태계가 빠르게 성장하고 있는 만큼, 앞으로도 다양한 가속기를 적극적으로 지원해 나갈 예정입니다.
참고 자료
Furiosa RNGD
Furiosa Cloud Native Toolkit (K8s 통합)
벤치마크 도구
Prefix Caching 배경 지식