Furiosa NPU에 LLM 모델을 포팅하고, LlamaIndex와 LangChain 기반 RAG 시스템을 구축한 과정을 공유드립니다.
들어가며
최근 LLM(Large Language Model) 서비스가 급격히 확산되면서, GPU 자원의 수급 문제와 높은 운영 비용이 주요 과제로 떠오르고 있습니다. 이러한 상황에서 NPU(Neural Processing Unit)는 AI 추론에 특화된 아키텍처와 우수한 전력 효율로 대안으로 주목받고 있습니다.
본 글에서는 Furiosa AI의 RNGD NPU에서 LLM 기반 RAG(Retrieval-Augmented Generation) 시스템을 구축하고 서비스한 경험을 기술적 관점에서 상세히 설명드리겠습니다.

1. 프로젝트 배경 및 목표
1.1 배경
본 프로젝트는 NIPA AI반도체 Farm 구축 및 실증 사업의 일환으로, LLM 기반 다국어 서비스를 국산 NPU에서 실증하는 것을 목표로 했습니다. 실증 대상 서비스는 다음 두 가지입니다:
- RAG 기반 다국어 챗봇: 문서 기반 질의응답 시스템
- LLM 번역 서비스: 실시간 다국어 번역
1.2 실증 목표 지표
GPU(NVIDIA A100) 대비 NPU의 성능을 객관적으로 비교하기 위해 다음 세 가지 지표를 설정했습니다:
| 지표 | 정의 | 측정 단위 | 목표 (RNGD) | 목표 (A100 대비) |
|---|---|---|---|---|
| 처리량 | 초당 토큰 생성수 | TPS | 200 이상 | 90% 이상 |
| 전성비 | 처리량 / 전력 소모량 | TPS/W | 1.3 이상 | 120% 이상 |
| 정확도 | n-gram 기반 번역 품질 | BLEU | 35 이상 | 90% 이상 |
2. 시스템 아키텍처
전체 시스템은 마이크로서비스 아키텍처로 설계하여 각 컴포넌트의 독립적인 확장과 배포가 가능하도록 구성했습니다.
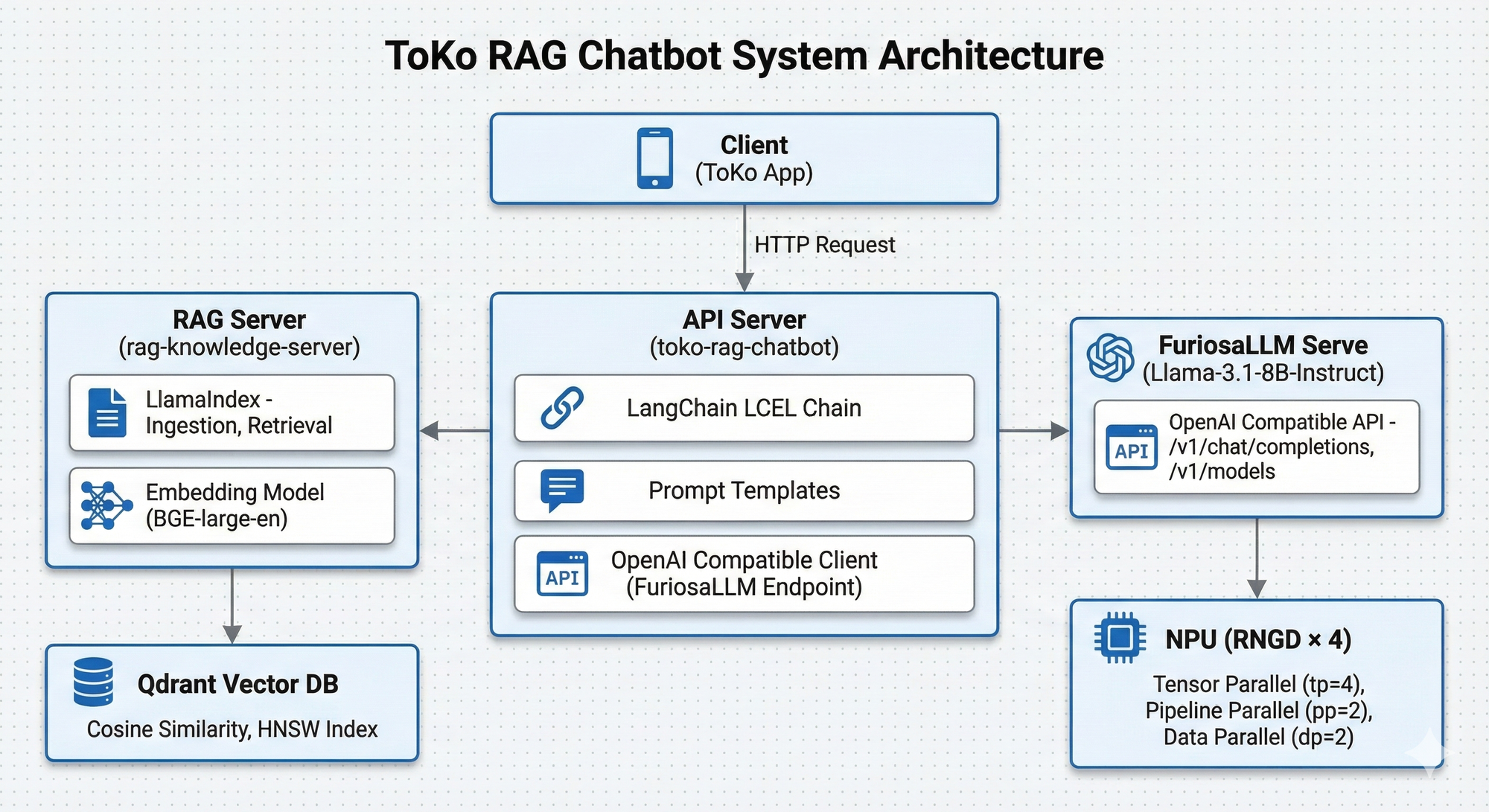
2.1 컴포넌트별 역할
| 컴포넌트 | 역할 | 기술 스택 |
|---|---|---|
| API Server | 사용자 요청 처리, RAG 체인 실행 | FastAPI, LangChain |
| RAG Server | 문서 Ingestion, Vector 검색 | FastAPI, LlamaIndex |
| Vector DB | 임베딩 벡터 저장 및 유사도 검색 | Qdrant |
| LLM Server | 토큰 생성 (추론) | FuriosaLLM Serve |
| NPU | LLM 추론 가속 | Furiosa RNGD |
3. RAG 파이프라인 구현
RAG 시스템은 크게 Ingestion(문서 수집) 과 Retrieval & Generation(검색 및 생성) 두 단계로 구성됩니다.
3.1 Ingestion Pipeline
문서를 벡터화하여 Vector DB에 저장하는 파이프라인입니다. LlamaIndex를 활용하여 구현했습니다.
파이프라인 흐름
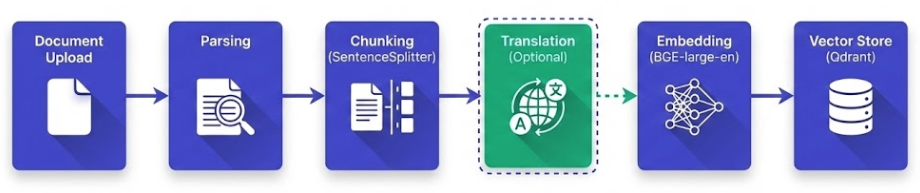
핵심 구현 코드
Ingestion Pipeline 코드 보기
from llama_index.core import Document
from llama_index.core.node_parser import SentenceSplitter
from llama_index.vector_stores.qdrant import QdrantVectorStore
async def ingest_documents(
documents: List[Document],
collection_name: str,
embed_model: BaseEmbedding,
node_parser: SentenceSplitter,
client: AsyncQdrantClient,
translator: TranslationClient,
target_language: Optional[str] = None,
):
# Step 1: Collection 생성 (동적 벡터 크기 결정)
dummy_embedding = embed_model.get_text_embedding("dummy text")
vector_size = len(dummy_embedding) # 1024 for BGE-large-en
await client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE),
)
vector_store = QdrantVectorStore(aclient=client, collection_name=collection_name)
# Step 2: Document를 Node로 분할 (Chunking)
nodes = node_parser.get_nodes_from_documents(documents, show_progress=True)
# Step 3: 다국어 검색 최적화를 위한 번역 (선택적)
if target_language:
original_texts = [node.get_content() for node in nodes]
translated_texts = await translator.translate(original_texts, target_language)
for i, node in enumerate(nodes):
node.set_content(translated_texts[i])
node.metadata["original_text"] = original_texts[i]
node.metadata["translated_to"] = target_language
# Step 4: Embedding 생성
for node in nodes:
node.embedding = embed_model.get_text_embedding(node.get_content())
# Step 5: Vector Store에 저장
await vector_store.async_add(nodes)
기술적 선택 사항
| 항목 | 선택 | 선택 이유 |
|---|---|---|
| Vector DB | Qdrant | 오픈소스 중 최고 성능, REST/gRPC 지원 |
| Embedding Model | BAAI/bge-large-en-v1.5 | MTEB 벤치마크 상위권, 다국어 지원 |
| Chunking | SentenceSplitter | 문장 경계 보존으로 의미 단위 유지 |
| Distance Metric | Cosine Similarity | 텍스트 임베딩에 일반적으로 적합 |
다국어 검색 최적화 전략
다국어 환경에서 검색 품질을 높이기 위해 다음 전략을 적용했습니다:
- 문서 번역 후 임베딩: 원문과 영어 번역본을 함께 저장
- 쿼리 번역: 사용자 질문을 영어로 번역하여 검색
- 원문 보존: 메타데이터에 원문 저장하여 응답 시 활용
# 검색 시 원문과 번역본 모두 활용
node.metadata["original_text"] = original_texts[i] # 한국어 원문
node.metadata["translated_to"] = "en" # 영어로 번역됨
3.2 Retrieval & Generation Pipeline
사용자 질문에 대해 관련 문서를 검색하고 LLM으로 응답을 생성하는 파이프라인입니다. LangChain LCEL(LangChain Expression Language) 을 활용하여 선언적으로 구현했습니다.
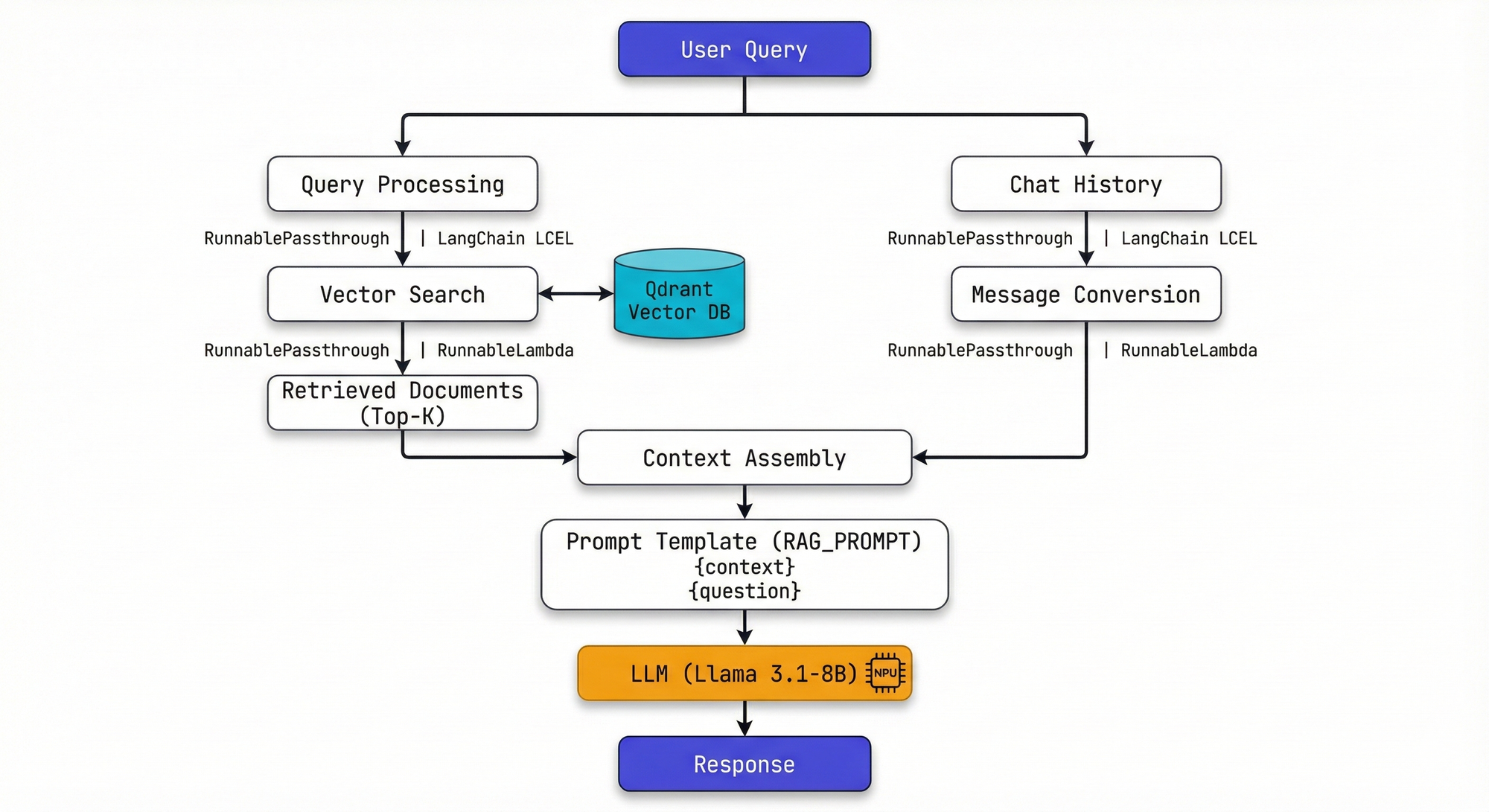
LangChain LCEL 기반 체인 구성
LangChain LCEL Chain 코드 보기
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# RAG 프롬프트 템플릿
RAG_PROMPT = ChatPromptTemplate.from_messages([
("system", """You are a helpful and professional AI assistant.
**Your Core Mission:**
Your goal is to answer user questions based *only* on the provided 'Context'.
**Key Instructions:**
1. **Assume User's Intent:** Handle typos and misspellings gracefully.
2. **NEVER Correct the User:** Provide direct answers without pointing out mistakes.
3. **Strictly Context-Based:** All answers must come from the provided Context.
4. **Handle Missing Information:** Politely state when information is unavailable.
Context:
{context}"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
# LCEL 체인 구성
def get_chain_for_request(request: ChatRequest) -> Runnable:
configured_llm = llm.bind(
temperature=request.temperature,
stop=["<|eot_id|>"], # Llama 3.1 EOS 토큰
)
retrieval_chain = (
RunnableLambda(retrieve_documents)
| RunnableLambda(_format_docs)
)
chain = (
RunnableLambda(lambda messages: {"messages": messages})
| RunnablePassthrough.assign(
question=itemgetter("messages") | RunnableLambda(_get_last_user_query),
)
| RunnablePassthrough.assign(
context=itemgetter("question") | retrieval_chain
)
| {
"chat_history": itemgetter("messages")
| RunnableLambda(_convert_to_langchain_messages)
| RunnableLambda(lambda msgs: msgs[:-1]), # 마지막 메시지 제외
"question": itemgetter("question"),
"context": itemgetter("context"),
}
| RAG_PROMPT
| configured_llm
| StrOutputParser()
)
return chain
LCEL 사용의 장점
- 선언적 구성: 파이프라인 흐름을 직관적으로 파악 가능
- 스트리밍 지원: 별도 코드 없이 자동으로 스트리밍 지원
- 비동기 처리:
ainvoke(),astream()자동 지원 - 배치 처리: 여러 입력을 효율적으로 병렬 처리
4. LLM 모델 선정 및 NPU 포팅
4.1 기반 모델 선정: Llama 3.1-8B-Instruct

RAG 및 번역 서비스를 위한 기반 모델로 Meta의 Llama 3.1-8B-Instruct를 선정했습니다.
모델 사양
| 항목 | 값 |
|---|---|
| Architecture | LlamaForCausalLM (Decoder-only) |
| Parameters | 8B |
| Hidden Size | 4,096 |
| Attention Heads | 32 (GQA) |
| Layers | 32 |
| Vocab Size | 128K (BPE) |
| Context Length | 128K tokens |
선정 이유
- Hallucination 억제: 주어진 컨텍스트를 정확히 활용하는 성향
- Instruction Following: 프롬프트 지시 수행 능력 우수
- NPU 공식 지원: Furiosa SDK에서 사전 컴파일된 아티팩트 제공
- 비용 효율성: 8B 파라미터로 latency/memory/cost 균형
4.2 NPU 포팅 과정에서의 기술적 도전
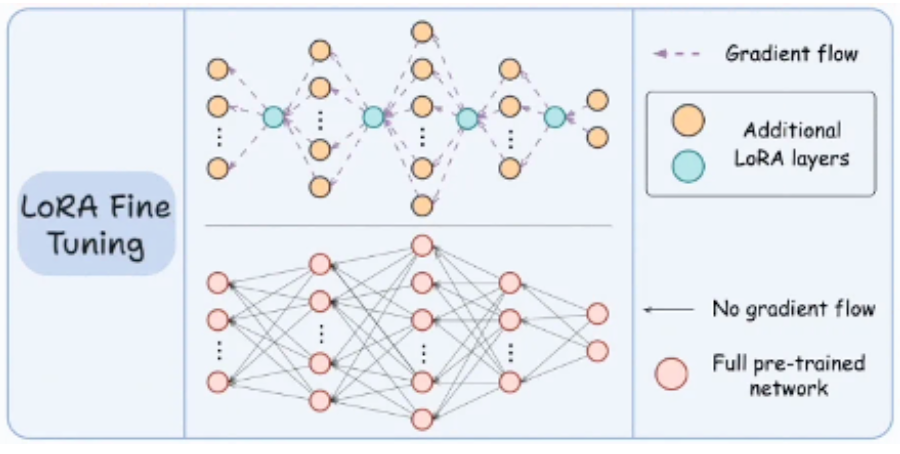
도전 1: LoRA 어댑터 미지원
초기에는 번역 품질 향상을 위해 LoRA(Low-Rank Adaptation) Fine-tuning을 계획했습니다.
LoRA 설정 코드 보기
# 초기 계획: LoRA Fine-tuning
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=8, # Rank
lora_alpha=16, # Scaling factor
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
)
그러나 Furiosa RNGD SDK가 LoRA 어댑터 구조를 지원하지 않아 NPU Runtime에 포팅이 불가능했습니다.
도전 2: Dynamic Cache 모델의 포팅 제약
번역 특화 모델인 X-ALMA-13B도 검토했으나, 매 추론 시점마다 동적으로 동작하는 Dynamic Cache 구조로 인해 Static FX Graph 캡처가 어려웠습니다.
Furiosa SDK 컴파일 방식:
torch.compile() → Static FX Graph 추출 → NPU 최적화 컴파일
Dynamic Cache 문제:
- 실행 시마다 캐시 크기가 변동
- Static Graph로 고정 불가
해결책: 프롬프트 엔지니어링
모델 가중치 수정 없이 프롬프트 최적화만으로 번역 품질을 확보하는 전략으로 전환했습니다.
번역 요청 빌드 코드 보기
def build_translation_request(req: TranslateRequest, text: str) -> dict:
src_lang = LANGUAGE_LABELS.get(req.source, "")
tgt_lang = LANGUAGE_LABELS.get(req.target, None)
# System Prompt: 역할 정의 및 출력 형식 제어
system_prompt = (
f"You are an expert translator. "
f"Your task is to accurately translate text from {src_lang} to {tgt_lang}. "
f"Provide only the translated text, without any additional explanations or introductions."
)
# User Prompt: Llama Native Instruction Format 활용
user_prompt = f"<s>[INST]Translate this from {src_lang} to {tgt_lang}:\n{src_lang}: {text}\n{tgt_lang}:[/INST]"
return {
"model": "furiosa-ai/Llama-3.1-8B-Instruct-FP8",
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
"temperature": 0.3, # 낮은 temperature로 일관성 확보
"stream": False,
}
프롬프트 최적화 기법
| 기법 | 설명 | 효과 |
|---|---|---|
| Instruction Format | <s>[INST]...[/INST] 구조 사용 |
Llama 모델의 학습 형식과 일치 |
| Role Definition | System prompt에 역할 명시 | 부가 설명 없이 번역만 출력 |
| Low Temperature | 0.3으로 설정 | 일관성 있는 번역 결과 |
| Few-shot Examples | 2-3개 예시 포함 (선택적) | 출력 형식 가이드 |
5. NPU 서빙 최적화
5.1 FuriosaLLM Serve 배포
Furiosa에서 제공하는 FuriosaLLM 서빙 프레임워크를 활용하여 모델을 배포했습니다. OpenAI API 호환 인터페이스를 제공하여 기존 코드 수정 없이 연동이 가능합니다.
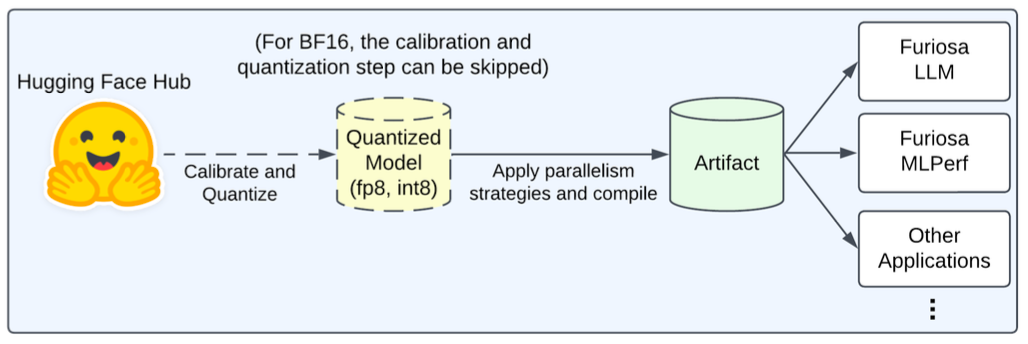
배포 명령어
FuriosaLLM 서버 실행 명령어 보기
# FuriosaLLM 서버 실행
FURIOSA_GENERATOR_WARMUP_ENABLE=1 furiosa-llm serve \
furiosa-ai/Llama-3.1-8B-Instruct-FP8 \
--tensor-parallel-size 4 \
--pipeline-parallel-size 2 \
--data-parallel-size 2 \
--max-seq-len 1024 \
--npu-queue-limit 1 \
--estimation-time-limit-ms 5
5.2 병렬화 전략
제공된 서버 스펙(RNGD × 4)에 맞게 병렬화 옵션을 최적화했습니다.
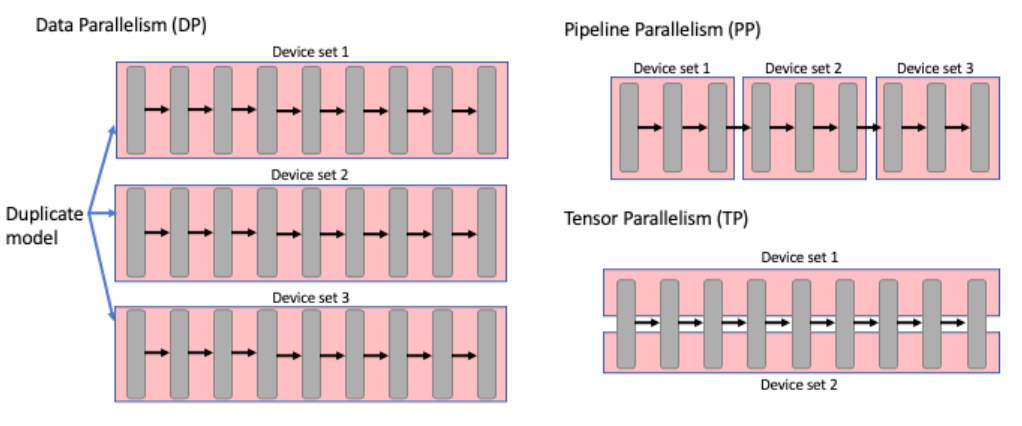
병렬화 옵션 설명
| 병렬화 방식 | 설정값 | 동작 방식 |
|---|---|---|
| Tensor Parallelism (tp=4) | 4 | 하나의 레이어 연산을 4개 NPU에 분할하여 동시 계산 |
| Pipeline Parallelism (pp=2) | 2 | 32개 레이어를 2그룹으로 나누어 순차 처리 |
| Data Parallelism (dp=2) | 2 | 동일 모델 2개 복제본으로 서로 다른 요청 병렬 처리 |
병렬화 조합의 의미
총 NPU 수 = tp × pp × dp = 4 × 2 × 2 = 16 (논리적)
실제 NPU 수 = 4 (RNGD 카드 4장)
→ 각 RNGD 카드가 tp 역할을 수행하며,
pp와 dp는 소프트웨어적으로 스케줄링
5.3 추가 최적화 파라미터
| 파라미터 | 값 | 설명 |
|---|---|---|
max-seq-len |
1024 | 실시간 번역 특성상 긴 시퀀스 불필요 |
npu-queue-limit |
1 | 요청당 NPU 큐 제한으로 지연 시간 최소화 |
WARMUP_ENABLE |
1 | 첫 요청 지연 시간 감소를 위한 웜업 |
6. 성능 벤치마크
6.1 테스트 환경
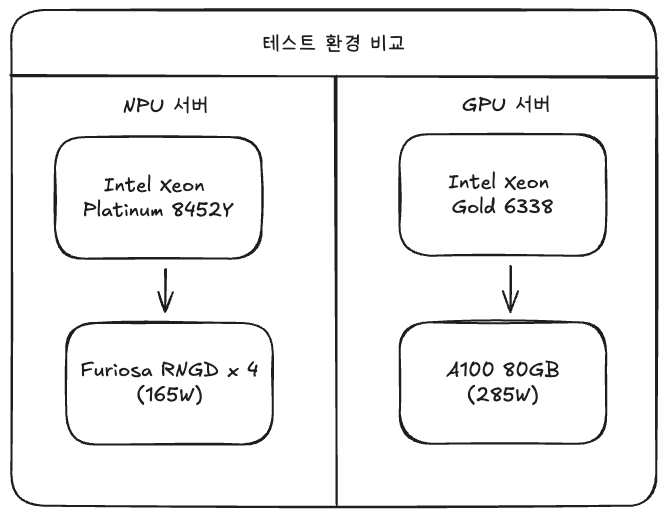
| 항목 | NPU 서버 | GPU 서버 |
|---|---|---|
| CPU | Intel Xeon Platinum 8452Y (36C) | Intel Xeon Gold 6338 (64C) |
| 메모리 | 512GB (컨테이너 192GB) | 1024GB (컨테이너 192GB) |
| 가속기 | Furiosa RNGD × 4 | NVIDIA A100 80GB |
| OS | Ubuntu 22.04 LTS | Ubuntu 22.04 LTS |
| SDK | Furiosa SDK 2025.3.1 | CUDA 12.2, vLLM 0.10.2 |
6.2 테스트 데이터셋
- 데이터 소스: X-ALMA (vi-en) + PhoMT 테스트셋
- 샘플 수: 10,000건 (랜덤 샘플링)
- 언어쌍: 베트남어 → 영어
6.3 벤치마크 스크립트
vLLM의 benchmark_serving.py를 활용하여 동일 조건에서 성능을 측정했습니다.
벤치마크 실행 명령어 보기
python benchmarks/benchmark_serving.py \
--backend vllm \
--model $MODEL_ID \
--port 8000 \
--dataset-name sharegpt \
--dataset-path $DATASET_PATH \
--request-rate 16 \
--num-prompts 10000 \
--enable-device-monitor "npu" \
--metric-percentiles "25,50,75,90,95,99" \
--percentile-metrics "ttft,tpot,itl,e2el" \
--save-result
6.4 측정 결과
10회 반복 측정 후 평균값을 산출했습니다.
| 지표 | NPU (RNGD) | GPU (A100) | NPU/GPU 비율 | 목표 달성 |
|---|---|---|---|---|
| 처리량 (TPS) | 361.2 | 361.6 | 99.9% | 달성 |
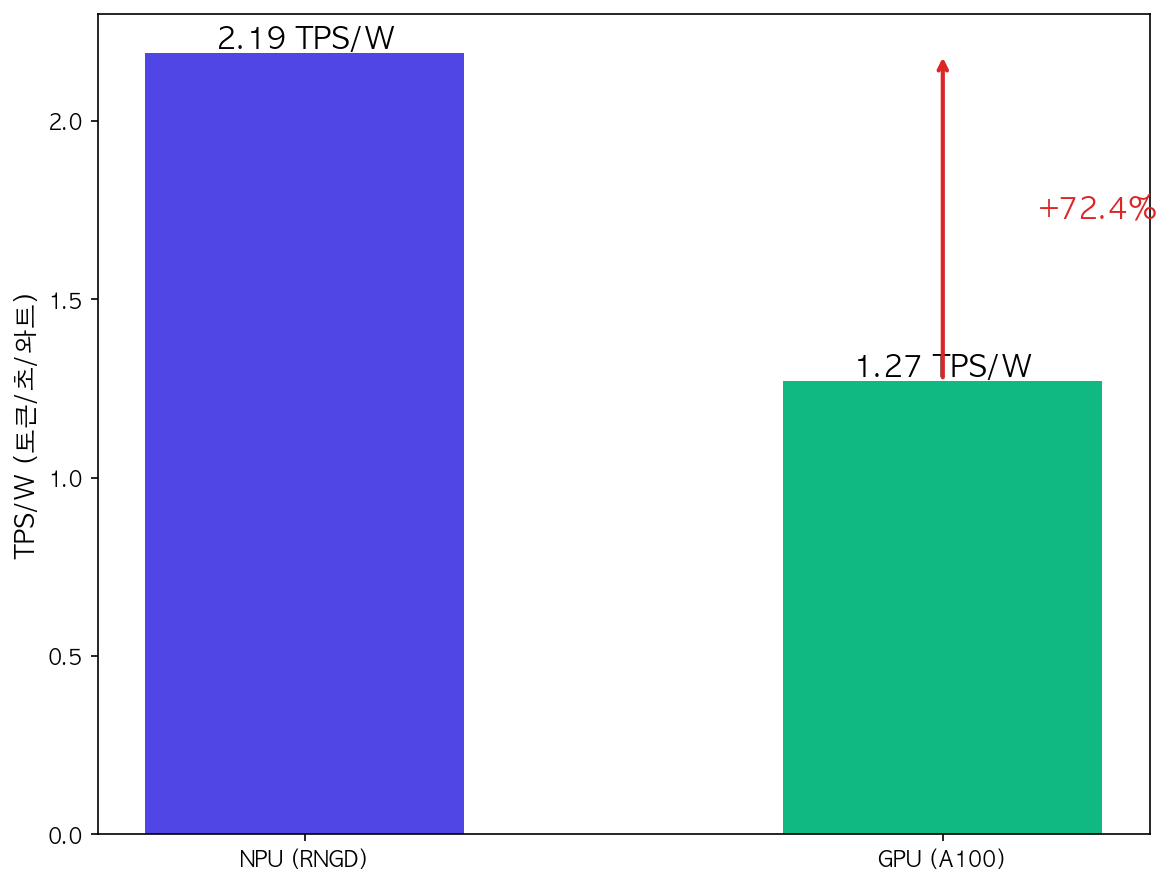
| 전성비 (TPS/W) | 2.19 | 1.27 | 172.4% | 초과 달성 |
| 정확도 (BLEU) | 36.95 | 36.99 | 99.9% | 달성 |
6.5 결과 분석
처리량 (Throughput)
NPU가 GPU와 동등한 수준의 토큰 생성 속도를 달성했습니다. 이는 FuriosaLLM의 최적화된 추론 엔진과 병렬화 전략이 효과적으로 작동했음을 의미합니다.
전성비 (Power Efficiency)
가장 주목할 만한 결과입니다. NPU가 GPU 대비 72.4% 더 높은 전력 효율을 보여주었습니다.
전성비 계산:
- NPU: 361.2 TPS / 165W = 2.19 TPS/W
- GPU: 361.6 TPS / 285W = 1.27 TPS/W
- 효율 향상: (2.19 - 1.27) / 1.27 = 72.4%
이는 대규모 서비스 운영 시 전력 비용의 상당한 절감을 의미합니다.
정확도 (BLEU Score)
동일한 모델과 프롬프트를 사용하므로 NPU와 GPU 간 정확도 차이는 미미합니다. 미세한 차이(0.04점)는 부동소수점 연산의 수치적 오차 범위 내입니다.
7. 운영 경험 및 인사이트
7.1 NPU 포팅 시 체크리스트
실제 프로젝트를 진행하며 얻은 NPU 포팅 체크리스트입니다:
- [ ] 모델 아키텍처 호환성: LoRA, Dynamic Cache 등 특수 구조 지원 여부 확인
- [ ] SDK 지원 모델 목록: 공식 지원 모델 우선 검토
- [ ] 양자화 옵션: FP8, INT8 등 지원 정밀도 확인
- [ ] 병렬화 전략: 하드웨어 스펙에 맞는 tp/pp/dp 설계
- [ ] 메모리 요구량: 모델 크기와 NPU 메모리 비교
7.2 RAG 시스템 최적화 팁
- 임베딩 모델 선택: 도메인과 언어에 맞는 모델 선택 (다국어: BGE, 한국어: KoSimCSE 등)
- 청킹 전략: 문장 단위 분할로 의미 보존, 오버랩 적용으로 컨텍스트 연결
- 검색 품질: Top-K 값 튜닝, 하이브리드 검색(Vector + Keyword) 고려
- 프롬프트 설계: 역할 명시, 컨텍스트 구조화, 출력 형식 가이드
7.3 프로덕션 운영 고려사항
| 항목 | 권장 사항 |
|---|---|
| 모니터링 | Prometheus + Grafana로 TPS, Latency, NPU 사용률 모니터링 |
| 로깅 | 요청/응답 로그 저장으로 품질 분석 및 디버깅 |
| 스케일링 | Kubernetes HPA로 트래픽 기반 자동 스케일링 |
| 폴백 | NPU 장애 시 GPU 또는 CPU 폴백 경로 구성 |
8. 마무리
본 프로젝트를 통해 Furiosa RNGD NPU에서 LLM 기반 RAG 시스템을 성공적으로 구축하고 서비스할 수 있음을 실증했습니다.
핵심 성과
- 처리량: GPU와 동등한 361 TPS 달성
- 전력 효율: GPU 대비 72% 향상된 전성비
- 정확도: BLEU 36.95로 목표 달성
시사점
NPU는 아직 GPU 대비 생태계 성숙도가 낮아 LoRA 등 일부 기능에 제약이 있지만, 추론 특화 워크로드에서는 뛰어난 전력 효율을 보여줍니다. 특히 대규모 서비스에서 TCO(Total Cost of Ownership) 절감에 큰 기여를 할 수 있습니다.
Furiosa SDK의 빠른 발전과 함께 이러한 제약들이 점차 해소될 것으로 기대하며, NPU 기반 AI 인프라의 확대에 기여할 수 있기를 바랍니다.
References
- Furiosa AI 공식 문서
- LlamaIndex Documentation
- LangChain Documentation
- HuggingFace Furiosa Llama 3.1 8B Instruct Model
- vLLM: Easy, Fast, and Cheap LLM Serving
한국 서버 개발자