영상 데이터를 효율적으로 벡터화하고, 대규모 유사도 검색을 안정적으로 수행하기 위한 설계와 구현 과정을 정리합니다.
들어가며
영상 기반 서비스나 데이터 분석 환경에서는 이 영상이 이미 처리된 영상과 동일하거나 유사한지를 빠르게 확인해야 하는 상황이 자주 발생합니다.
예를 들어 다음과 같은 경우가 있습니다.
- 대규모 영상 데이터 처리 과정에서 이미 분석이 완료된 영상이 다시 유입되었는지 확인해야 하는 경우
- 서로 다른 경로로 수집된 영상들 중 실제로는 동일한 장면이나 동일한 소스를 기반으로 한 영상이 포함되어 있는지 점검해야 하는 경우
- 영상 포맷, 해상도, 인코딩 방식이 달라졌더라도 내용 자체가 동일한 영상인지 판별해야 하는 경우
이러한 상황에서 단순한 파일 해시나 메타데이터 비교만으로는 한계가 있으며,
영상의 내용 자체를 기준으로 비교할 수 있는 방법이 필요합니다.
이 글에서는 이러한 문제를 해결하기 위해 고민했던 과정과, EfficientNetV2 기반 특징 추출 + FAISS 벡터 검색을 활용한 영상 유사도 검색 시스템의 전체적인 설계를 공유합니다.
1. 영상 유사도 판단 문제와 접근 방식
1.1 영상 기반 데이터 처리 환경의 특성
영상 데이터는 이미지나 텍스트와 달리 데이터 크기가 크고, 내부 구성 또한 인코딩 방식과 표현 형태에 따라 다양하게 변화합니다.이러한 특성으로 인해 단순한 파일 단위 비교 방식은 여러 한계를 가집니다.
영상은 유통·저장·처리 과정에서 다양한 후처리가 적용될 수 있습니다.
- 해상도 변경
- 인코딩 방식 변경 (H.264, VP9, AV1 등)
- 컨테이너 포맷 변경 (MP4, MKV, AVI 등)
- 자막 삽입, 로고 오버레이, 경미한 크롭 등 시각적 후처리
이 때문에 동일한 영상이라 하더라도 파일 수준이나 메타데이터 수준의 비교로는 동일 여부를 정확히 판단하기 어렵습니다.
하지만 시각적 후처리의 경우에는 실제 시각적 내용이 크게 바뀌지 않는 경우가 많습니다.

그래서 영상 데이터의 동일성이나 유사성을 판단하기 위해서 파일이나 메타데이터의 비교가 아닌, 영상의 시각적 특징을 기준으로 비교하는 방식을 이용했습니다.
1.2 시각적 특징 기반 유사성 판단
앞서 살펴본 것처럼, 자막 삽입이나 로고 오버레이와 같은 시각적 후처리는 영상의 일부 영역에 국한되어 적용되는 경우가 많으며, 영상의 전체적인 시각적 구성이나 주요 장면 자체를 크게 변경하지는 않습니다.
이러한 특성을 바탕으로, 본 시스템에서는 영상 파일 자체를 비교하는 대신 영상 프레임 간의 시각적 특징을 추출하여 비교하는 방식을 선택했습니다.
구체적으로는, 이미지 인식 분야에서 검증된 CNN(Convolutional Neural Network) 기반 모델을 활용하여 영상 프레임으로부터 고수준 시각적 특징을 벡터 형태로 추출하고, 이 특징 벡터를 기준으로 영상 간 유사성을 판단합니다.
이와 같은 접근 방식은 시각적 후처리로 인한 국소적인 차이에 덜 민감하면서도, 동일한 영상 콘텐츠를 안정적으로 비교할 수 있는 기반을 제공합니다.
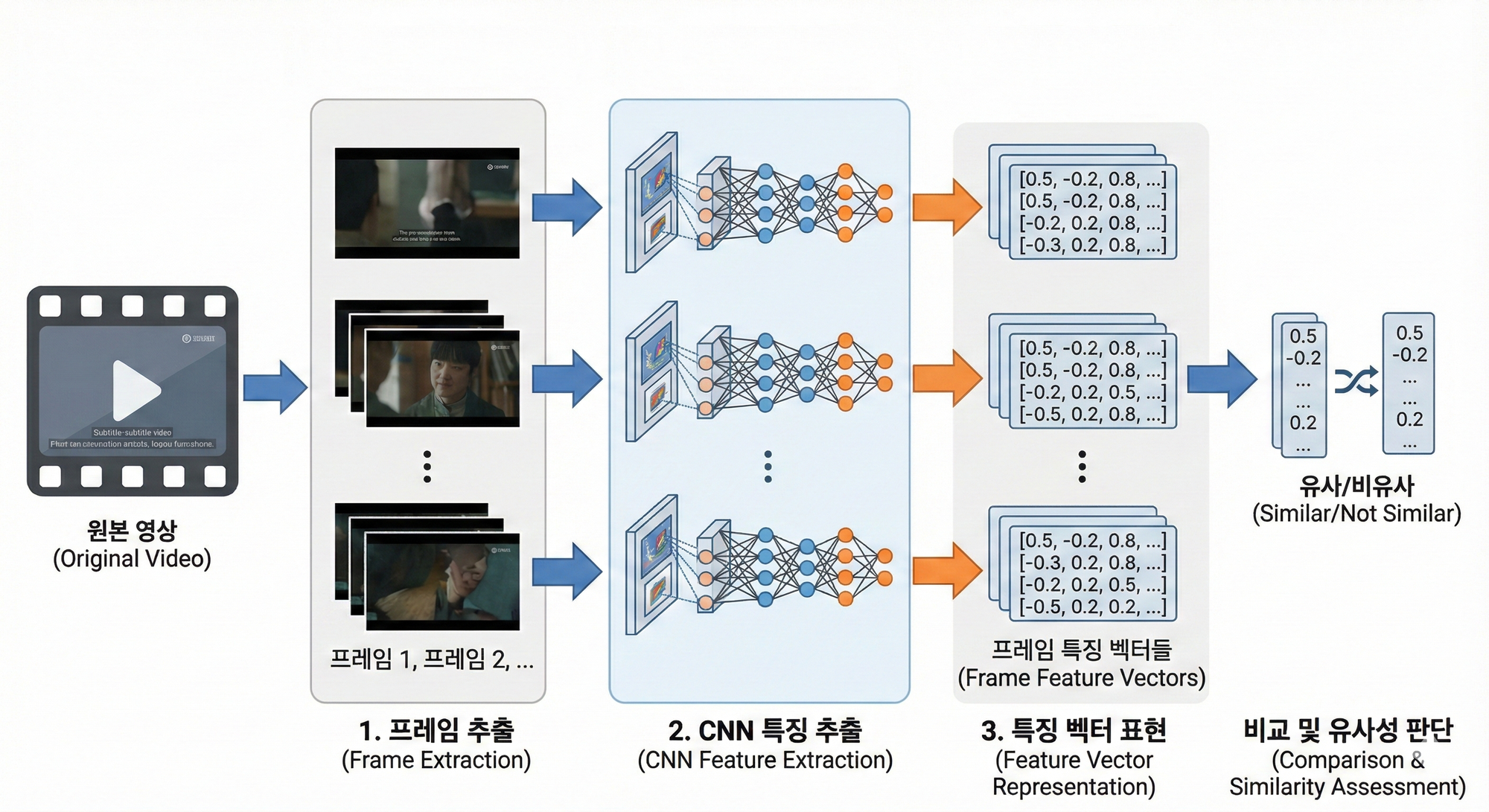
2. 시스템 구성
2.1 시스템 처리 흐름
시스템의 큰 흐름은 다음과 같습니다.
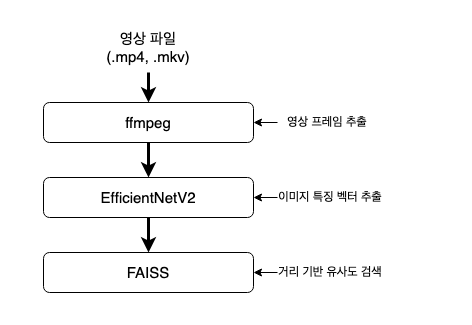
이 시스템은 다음 세 가지 핵심 요소로 구성됩니다.
- 영상을 초단위로 프레임 추출
- 영상 프레임 이미지에서 특징을 추출하여 벡터로 변환
- 대규모 벡터를 빠르게 검색할 수 있는 인덱스 구성
3. 특징 추출 모델 설계
3.1 EfficientNetV2 선택 이유
특징 추출 백본으로 여러 후보가 있었습니다.
| 후보 | 장점 | 단점 |
|---|---|---|
| ResNet 계열 | 안정적, 널리 검증됨 | 연산량 대비 효율 아쉬움 |
| MobileNet | 경량, 빠름 | 표현력 한계 |
| Vision Transformer | 글로벌 컨텍스트 | 연산 비용, 서빙 부담 |
| EfficientNetV2 | 성능 대비 효율 우수 | 복잡한 구조 |
EfficientNetV2는 다음 이유로 선택되었습니다.
- ImageNet 사전 학습 가중치 제공
- CNN 기반으로 서빙 안정성 우수
- 동일 해상도 대비 높은 표현력
- 다양한 크기(S/M/L) 모델 선택 가능
3.2 EfficientNetV2 특징 추출 구조
EfficientNetV2를 분류 모델이 아닌 특징 추출 백본(backbone) 으로 사용했습니다.
특징 추출 백본 사용 시
- ImageNet으로 사전 학습된 가중치를 그대로 활용함으로써,추가적인 대규모 학습 과정 없이도 안정적인 시각적 특징을 추출할 수 있습니다.
- 백본을 고정한 상태로 특징을 추출하기 때문에,모델 재학습이나 파라미터 튜닝 없이도 일관된 기준의 특징 벡터를 지속적으로 생성할 수 있습니다.
실제 사용한 구조는 다음과 같습니다.
EfficientNetV2-S (include_top=False)
→ GlobalAveragePooling2D
→ Dense(1024)
# 모델 코드
backbone = tf.keras.applications.EfficientNetV2S(
weights="imagenet",
include_top=False, # 분류 head 제거
input_shape=(224, 224, 3)
)
model = tf.keras.Sequential([
backbone, # (None, 7, 7, 1280)
tf.keras.layers.GlobalAveragePooling2D(), # (None, 1280)
tf.keras.layers.Dense(1024) # (None, 1024)
])
3.3 각 레이어의 역할
EfficientNetV2 Backbone
- 입력 이미지에서 고수준 시각 특징 추출
- 출력 형태:
(H, W, 1280)
Global Average Pooling (GAP)
- 공간 차원(H, W)을 평균으로 제거
- 위치 정보는 제거하고 채널별 요약만 유지
- 출력 형태:
(1280,)
Dense (1024)
- 1280차원 벡터를 1024차원으로 선형 투영
- FAISS 인덱싱에 적합한 크기로 조정
- 출력 형태:
(1024,)
GAP와 Dense 레이어는 백본에 의해 출력된 특징을 프로젝트 목적에 맞게 변환하기 위한 후처리 레이어로 추가되었습니다.
3.4 사전 학습(pretrained) 모델 사용에 대한 고려
EfficientNetV2는 ImageNet으로 사전 학습된 가중치를 사용했습니다.
- 영상 데이터만으로 대규모 학습은 비용이 큼
- 일반적인 시각 패턴(edge, texture 등)은 이미 학습되어 있음
- 적은 데이터에서도 안정적인 특징 표현 가능
4. 벡터 기반 유사도 검색 설계
4.1 FAISS 선택 이유
영상 프레임 벡터는 빠르게 누적됩니다.
- 영상 1개 → 수십 ~ 수백 프레임
- 전체 데이터셋 → 수십만 ~ 수백만 벡터
이러한 환경에서는 brute-force 검색이 현실적이지 않으며,
FAISS는 다음 요구를 충족합니다.
- 고차원 벡터 검색에 특화
- CPU/GPU 모두 지원
- 다양한 인덱스 구조 제공
- 대규모 데이터에서도 안정적인 성능
4.2 FAISS 인덱스 구조
초기 설계에서는 정확도 우선을 기준으로 IndexFlatL2를 사용했습니다.
index = faiss.IndexFlatL2(1024)
index.add(embeddings)
특징은 다음과 같습니다.
- 모든 벡터를 그대로 저장
- L2 거리 기반 정확 검색
- 구현 단순, 디버깅 용이
데이터 규모 확장 시에는 Faiss의 IVF, HNSW, PQ 계열 인덱스로의 확장도 고려 가능합니다.
4.3 인덱스 저장 및 로딩 전략
운영 환경에서는 벡터 배열이 아닌 FAISS 인덱스 자체를 저장합니다.
- 인덱스 재구성 비용 제거
- 서버 재시작 시 빠른 복원
- 벡터 차원 및 거리 기준 일관성 유지
faiss.write_index(index, "index.idx")
FAISS 인덱스는 벡터 검색에 필요한 정보만을 관리하며, 각 벡터가 어떤 영상이나 프레임에 해당하는지에 대한 메타데이터는 직접 저장하지 않습니다.
이를 보완하기 위해, 본 시스템에서는 FAISS 인덱스와 별도로 벡터와 메타데이터를 연결하는 매핑 정보(Mapper)를 함께 관리합니다.
FAISS 인덱스: 벡터 및 검색 구조 관리
Mapper: 벡터 ID ↔ 영상 식별자, 프레임 위치 등의 메타데이터 매핑
이 매핑 정보는 일반적으로 직렬화된 파일 형태로 저장되며, 인덱스 로딩 시 함께 복원되어 검색 결과를 해석하는 데 사용됩니다.
4.4 FAISS 기반 벡터 유사도 검색의 개념
FAISS는 이미지나 영상 자체를 직접 비교하지 않고, 각 프레임을 통해 생성된 고정 차원의 특징 벡터를 기준으로 유사도를 계산합니다.
각 벡터는 고차원 공간상의 한 점으로 볼 수 있으며, FAISS는 이 공간에서 서로 가장 가까운 벡터를 빠르게 찾는 역할을 수행합니다. 즉, “두 프레임이 얼마나 비슷한가?”라는 질문을 “두 특징 벡터 사이의 거리가 얼마나 가까운가?”라는 문제로 변환합니다.
본 시스템에서는 L2 거리 기반 인덱스를 사용하여, 입력 프레임 벡터와 기존에 저장된 벡터들 사이의 거리를 계산합니다. 이때 거리가 가까울수록 두 프레임이 시각적으로 유사하다고 판단할 수 있습니다.
5. 유사도 검색
5.1 유사도 검색 처리 흐름
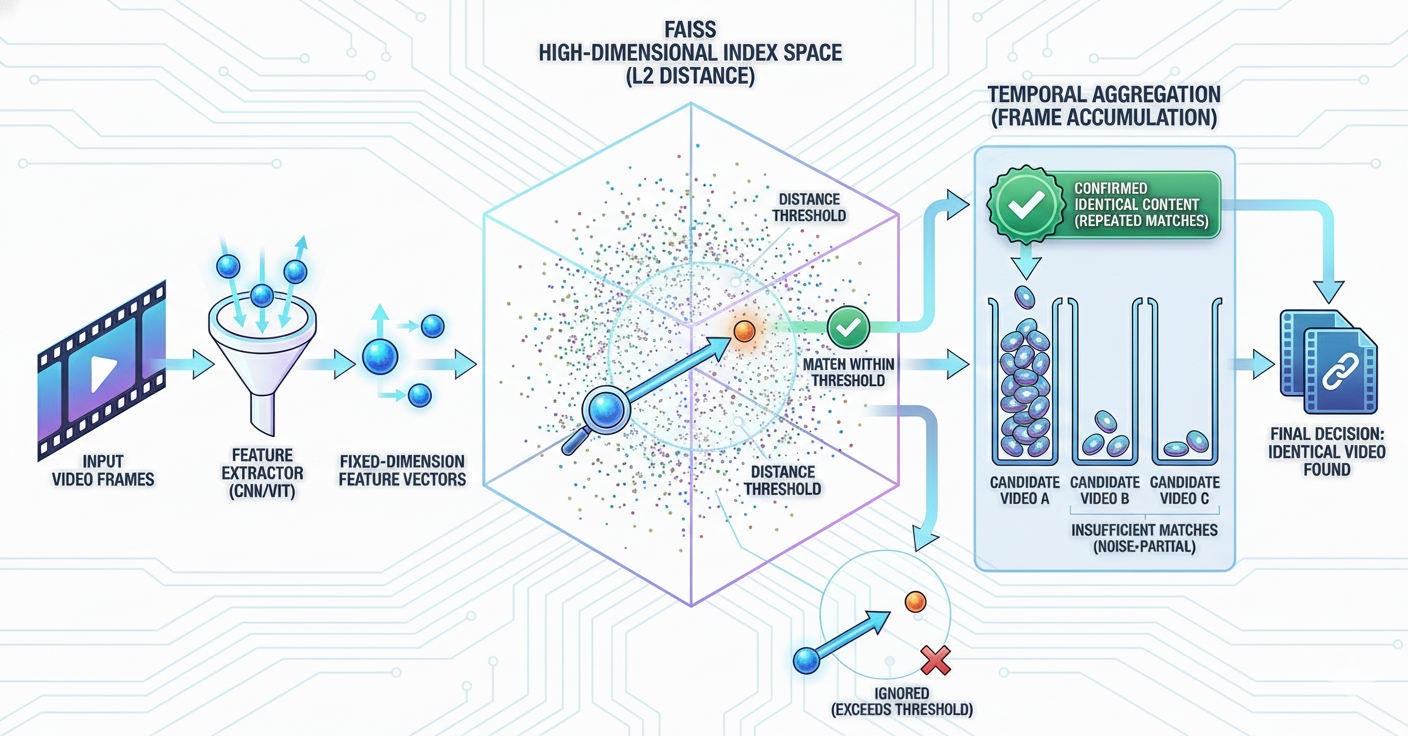
유사도 검색 요청은 다음과 같은 절차로 처리됩니다.
- 입력 영상에서 일정 간격으로 프레임을 추출합니다.
- 각 프레임을 특징 벡터로 변환합니다. (인덱스에 저장된 벡터와 동일한 방식으로 생성)
- FAISS 인덱스를 이용해 각 프레임 벡터에 대해 가장 유사한 벡터 후보와 거리 값을 검색합니다.
- 거리 값이 사전에 설정된 기준을 만족하는 결과만을 선별하여 결과를 종합합니다.
- 프레임별 결과를 누적 집계하여, 특정 영상이 여러 프레임에서 반복적으로 매칭되는지를 확인합니다.
- 그 결과, 다수의 프레임에서 동일한 영상으로 판단되는 경우에만 입력 영상이 기존 데이터와 동일한 콘텐츠로 판단됩니다.
이와 같은 처리 흐름을 통해 일부 프레임의 노이즈나 후처리 영향을 완화하면서도, 영상에 대한 안정적인 유사도 판단이 가능하도록 설계했습니다.
6. 마치며
이 글에서는 EfficientNetV2와 FAISS를 활용한 영상 유사도 검색 시스템의 전체적인 설계와 구현 과정을 정리했습니다.
핵심 내용은 다음과 같습니다.
- 영상은 프레임 단위로 분해하여 처리
- EfficientNetV2를 특징 추출 백본으로 활용
- FAISS를 통해 대규모 벡터 검색 구현
- 인덱스 중심 구조로 성능과 운영 안정성 확보
이 구조는 특정 도메인에 한정되지 않으며, 다양한 영상 분석 및 검색 문제에 확장 적용할 수 있습니다.
참고 자료
한국 서버 개발자