들어가며
최근 AI 산업은 초거대 모델의 등장으로 인해 연산 자원 확보가 곧 경쟁력이 되는 시대에 진입했습니다. 그러나 NVIDIA GPU 중심의 서버향 연산 자원 독점은 공급망 불안정, 전력 소모, 비용 급상승이라는 삼중고를 야기하고 있습니다.
이러한 상황에서 특정 AI 연산에 최적화된 NPU(Neural Processing Unit)의 전략적 가치가 주목받고 있습니다. 특히 실시간 비전 데이터 처리가 요구되는 산업 현장에서는 데이터의 중앙 집중화를 탈피하고 현장에서 즉각적인 추론을 수행하는 엣지 컴퓨팅(Edge Computing) 인프라로의 패러다임 전환이 필수적입니다.
본 글에서는 엣지-서버 NPU 연합 프레임워크를 설계하고 구현한 과정을 기술적 관점에서 상세히 설명합니다. 이 프로젝트는 총 25개월 간 진행되었으며, 국산 AI 반도체인 사피온(SAPEON) 을 포함한 이기종 NPU 통합에 성공하였습니다.
1. 프로젝트 배경 및 목표
1.1 기존 시스템의 핵심 페인 포인트(Pain Points)
| 문제점 | 상세 설명 | 영향 |
|---|---|---|
| 네트워크 지연시간 | 퍼블릭 클라우드 기반 시스템은 4G 및 한국 AWS 리전 기준 평균 250ms 지연 | 실시간 처리 불가 |
| 엣지 NPU 리소스 제약 | 단일 모델 구동에 그치며, 정지 영상에서도 NPU 풀 가동 | 경제적 손실, 이용률 저하 |
| 데이터 보안 고립 | 폐쇄망 환경에서 외부 전송 제한으로 모델 업데이트 불가 | 성능의 고착화 |
네트워크 지연시간의 물리적 한계
- 퍼블릭 클라우드 기반 시스템은 4G 및 한국 AWS 리전 기준으로 평균 250ms 수준의 지연을 보입니다.
- 5G 도입 시 100ms 이하로 단축이 가능하나, 산업 현장의 네트워크 불안정성을 고려할 때 진정한 실시간성 확보를 위해서는 80ms 이내의 안정적 지연시간 보장이 필수적입니다.
엣지 NPU의 리소스 제약 및 경제적 비효율
- 엣지 NPU는 물리적 연산 자원이 제한되어 단일 모델 구동에 그치는 경우가 많습니다.
- CCTV 비전 시스템의 경우, 실제 탐지 대상이 없는 정지 영상 상태에서도 NPU가 풀 가동되는 낭비가 발생합니다.
데이터 보안 및 폐쇄망 환경의 고립
- 보안이 중시되는 현장 데이터는 외부 전송이 엄격히 제한됩니다.
- 결과적으로 모델의 지속적인 학습/업데이트가 불가능해지는 성능 고착화 문제가 발생합니다.
1.2 실증 목표 지표
| 지표 | 정의 | 목표치 | 기술적 의의 |
|---|---|---|---|
| 이종 모델 동시 추론 | 단일 스트림에서 동시 구동 가능한 모델 수 | 3개 이상 | 다중 분석 파이프라인 구현 |
| 네트워크 지연시간 | 엣지-서버 간 추론 요청 응답 시간 | 80ms 이내 | 실시간성 확보 |
| 추론 이용률 향상 | 기존 대비 NPU 활용 효율 | 3배 이상 | 경제적 효율성 극대화 |
| 국산 AI 반도체 실증 | 통합 가능한 국산 NPU 종류 | 1개 이상 | 국내 생태계 기여 |
| 폐쇄망 학습 검증 | 연합 학습으로 검증된 모델 수 | 2개 모델 | 보안성과 성능의 양립 |
1.3 프로젝트 목표: 연합 프레임워크의 논리
기존 방식
[엣지] ─── 전체 데이터 ───> [클라우드 서버] ─── 결과 ───> [엣지]
(높은 지연, 보안 위험)
연합 프레임워크 방식
[엣지 클러스터] ── 1차 추론 ──> 정밀 분석 필요시만 ──> [서버 클러스터]
(실시간성) (선별적 위임) (고정밀도)
- 엣지: 가벼운 1차 추론(실시간성)
- 서버: 정밀 분석 워크로드 처리(정확도)
- 서버의 Federated Inference Controller가 자원을 배분/오케스트레이션
2. 시스템 아키텍처
2.1 설계 원칙
| 설계 원칙 | 구현 방식 | 이점 |
|---|---|---|
| 지능형 분산 제어 | Federated Inference Controller | 워크로드 최적 배분 |
| 하드웨어 추상화 | Pod 기반 워크로드 캡슐화 | 이기종 NPU 통합 관리 |
| 인터페이스 격리 | Side-car Pattern 채택 | NPU 드라이버/런타임 간섭 최소화 |
2.2 계층적 구조: Edge Zone과 Server Zone
시스템은 보안 경계에 따라 Edge Zone(Secure)과 Server Zone으로 구분됩니다.
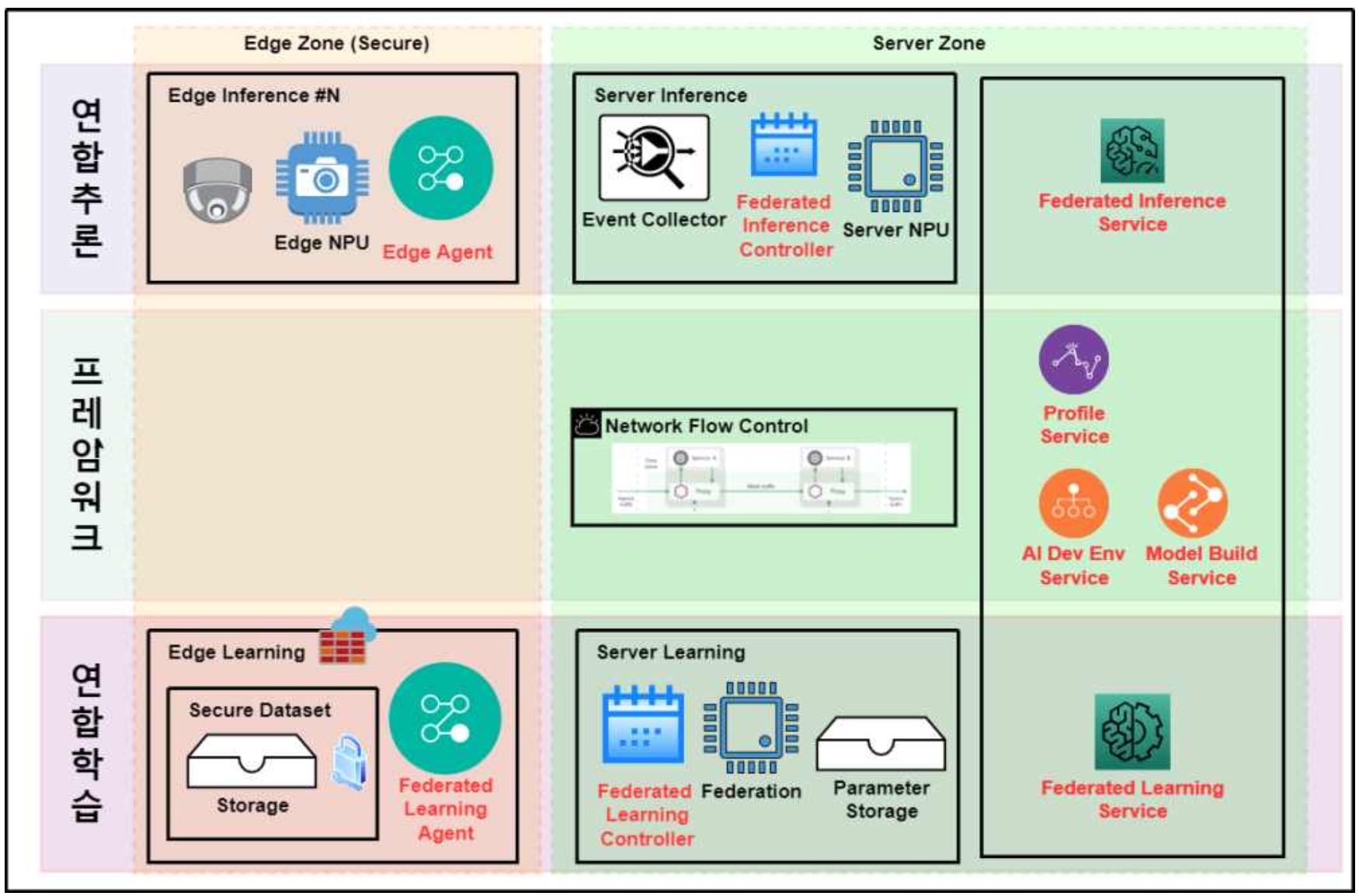
2.3 핵심 컴포넌트
1) 연합 추론 서비스 (Federated Inference Service)
엣지 에이전트와 서버 컨트롤러 간의 협력을 통해 이종 모델의 동시 추론 워크로드를 오케스트레이션합니다.
| 기능 | 설명 |
|---|---|
| 워크로드 분배 | 복잡도 기반 연산 위치 결정 |
| 모델 관리 | 이종 모델 동시 구동 조율 |
| 장애 복구 | 노드 장애 시 자동 재배치 |
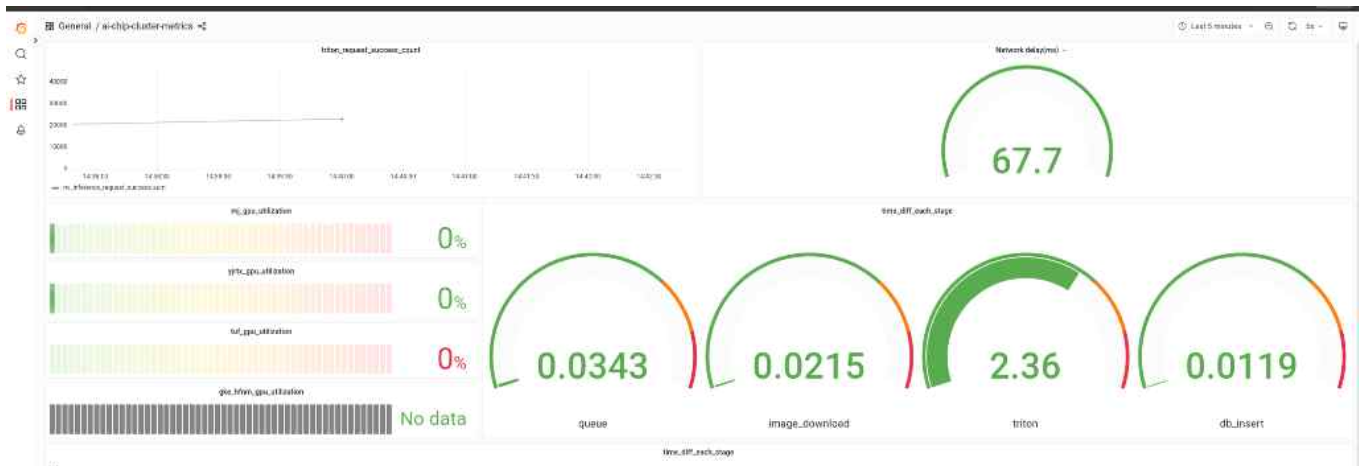
2) 프로파일러 (Profile Service)
엔지니어 친화적인 SDK/CLI 형태와 UI 모니터링을 함께 제공합니다.
3. AI 개발 환경 서비스 (AI Dev Env)
엔지니어에게 통합 개발 환경을 제공하여 개발-배포 주기를 단축합니다.
| 제공기능 | 도구 | 용도 |
|---|---|---|
| 노트북 환경 | Jupyter Notebook | 실험 및 프로토타이핑 |
| 하이퍼파라미터 튜닝 | 하이퍼파라미터 튜닝 도구(Kubeflow 기반 등) | 모델 최적화 |
| Artifact 저장소 | MinIO (S3 호환) | 모델/데이터 버전 관리 |
| 인증/인가 | Cloud ID (OIDC) | 보안 접근 제어 |
4. 네트워크 흐름 제어 (Network Flow Control)
[서비스 메시를 활용한 트래픽 제어 및 보안]
민감 데이터의 트래픽 제어를 위해 오픈소스 서비스 매시인 Istio를 도입하여, 트래픽 라우팅의 유연성을 확보하고 데이터 전송 전 구간에 걸친 보안 정책을 수립했습니다.
# Service Mesh YAML 설정 예시
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: inference-routing
spec:
hosts:
- inference-service
http:
- match:
- headers:
x-priority:
exact: "high"
route:
- destination:
host: server-inference
port:
number: 8080
- route:
- destination:
host: edge-inference
port:
number: 8080
---
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: edge-mtls
spec:
selector:
matchLabels:
zone: edge
mtls:
mode: STRICT
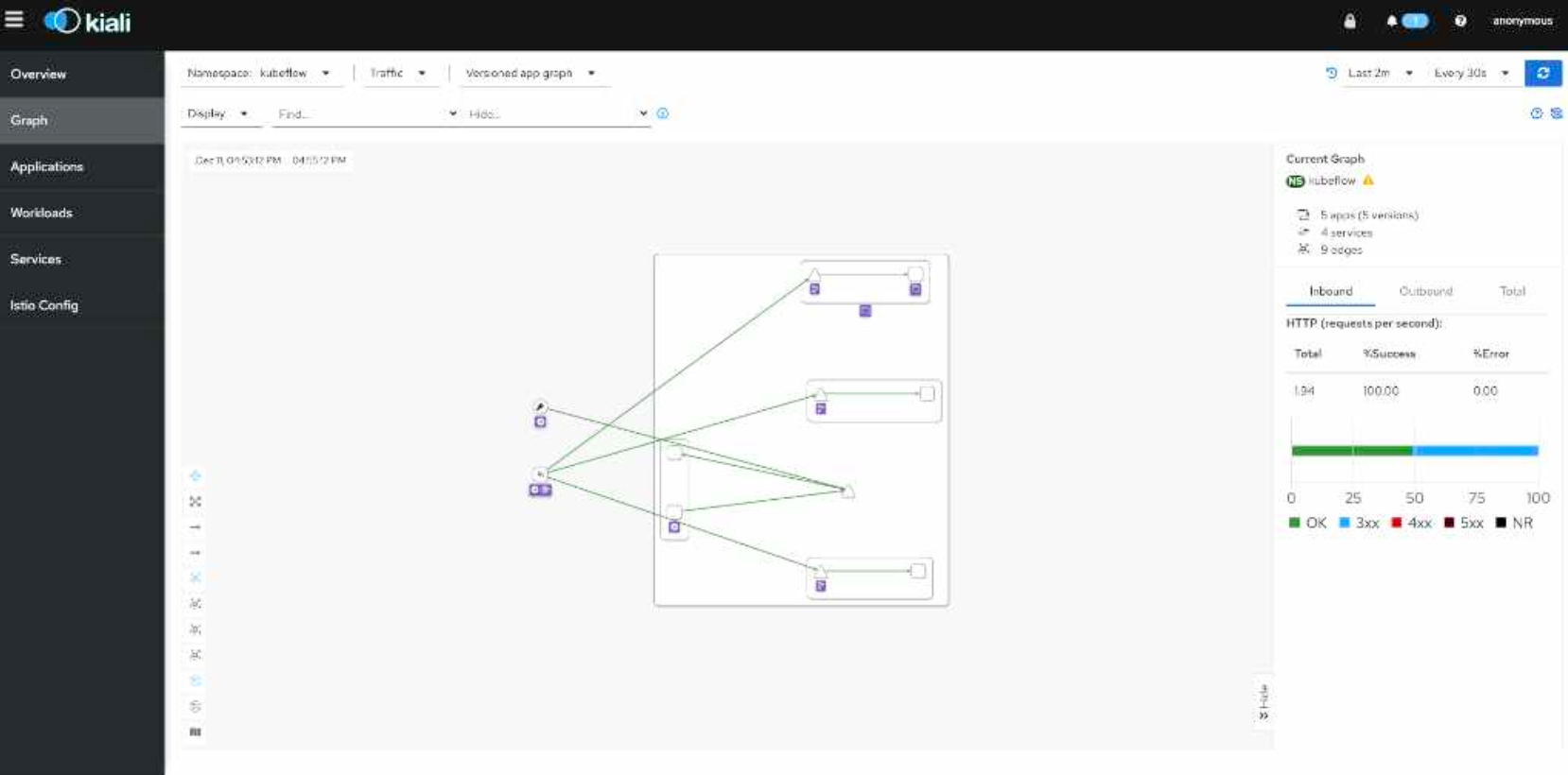
Kiali를 통한 트래픽 가시화
마이크로서비스 간의 통신 흐름은 Kiali를 통해 시각화했습니다. 설정한 라우팅 정책이 의도대로 동작하는지 실시간으로 검증하고, 트래픽 병목 지점이나 비정상적인 연결 시도를 즉각적으로 파악할 수 있는 관측 체계를 마련했습니다.
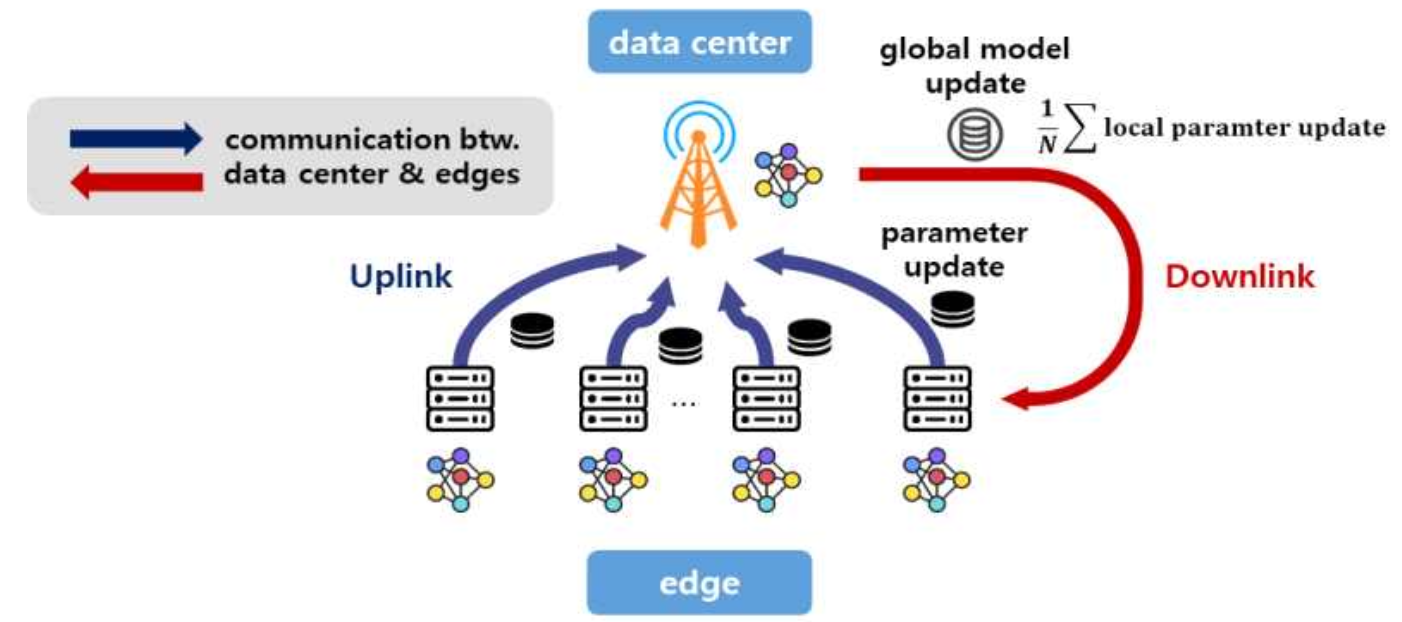
5. 연합 학습 서비스 (Federated Learning Service)
폐쇄망인 Edge AI반도체 클러스터와 연결된 Edge Zone에서 데이터를 수집한 뒤, 서버와 모델 파라미터만을 동기화 모델을 업데이트 하는 연합학습 형태로 모델 업그레이드를 수행합니다.
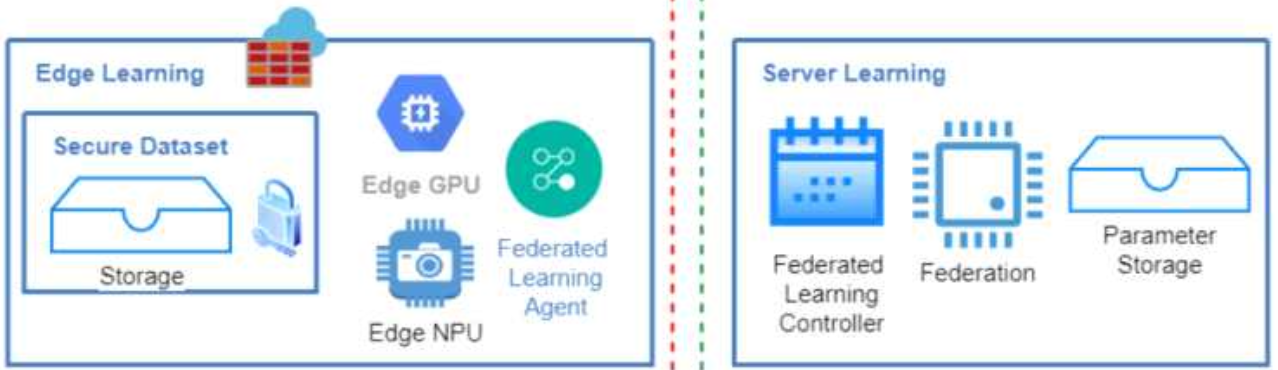
연합 학습을 위한 엣지-서버NPU 간 통신 시스템
3. 연합 추론 서비스 및 NPU 프로비저닝 구현
3.1 KubeEdge 기반의 클라우드-엣지 통합 제어 평면
분산된 엣지 노드를 통합 관리하기 위해 KubeEdge를 도입하였습니다.
KubeEdge는 서버의 CloudCore와 엣지의 EdgeCore가 메시지 버스를 통해 통신하며 엣지 단의 추론 수행을 보장합니다.
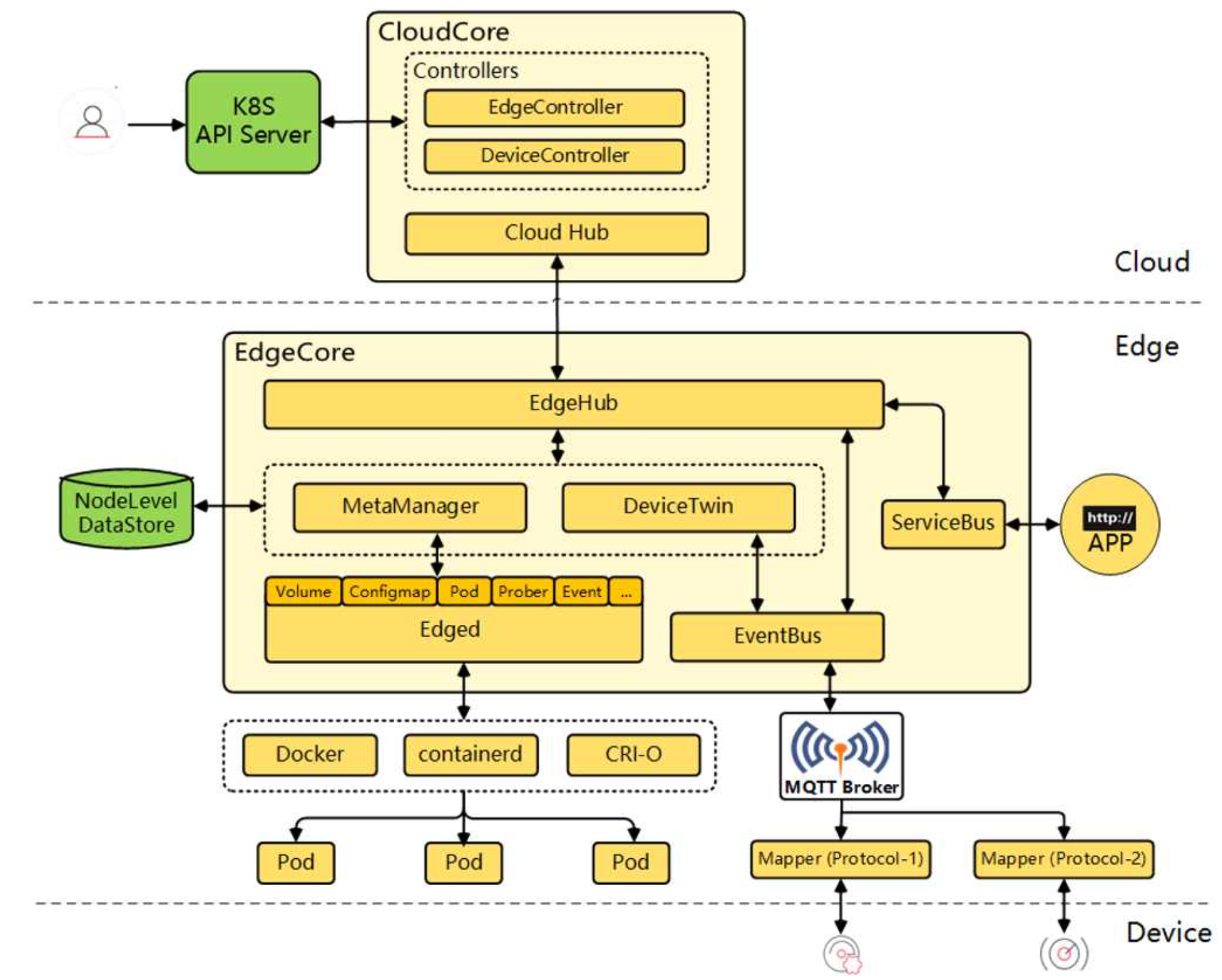
3.2 지능형 워크로드 스케줄링 및 아키텍처 설계
엣지 디바이스의 제한된 연산 자원을 극대화하기 위해서는 모든 추론을 로컬에서 처리하기보다, 작업의 경중과 복잡도에 따라 유연하게 자원을 배분하는 협업형 스케줄링 이 필수적입니다.
이를 위해 엣지와 서버 간 워크로드를 동적으로 분산하는 스케줄러 아키텍처를 설계하였습니다.
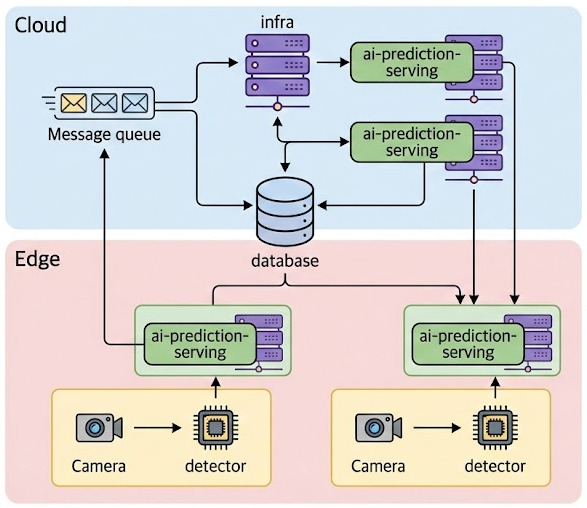
-
Edge Layer (로컬 추론): 엣지 노드에 등록된 기본 추론(Basic Inference)은 디바이스 내부의 Detector와 Serving 엔진을 통해 즉각적으로 수행됩니다.
-
Cloud Layer (심화 추론): 엣지에서 처리하기 어려운 고부하 태스크나 미등록 추론 요청은 Message Queue에 인큐(Enqueue)됩니다.
-
Dynamic Scheduler: 메시지 큐에 쌓인 요청은 스케줄링 알고리즘에 따라 최적의 서버 노드로 배분되어 심화 추론을 거치게 됩니다.
3.3 NPU 프로비저닝 스케줄러
하드웨어 가속기를 컨테이너 환경에 도입하려면 오케스트레이션 레이어의 리소스 인식과 런타임 레이어의 호출 구조를 잇는 설계가 뒷받침되어야 합니다.
이를 위해 진행한 SAPEON Device Plugin 개발 및 Triton Custom Backend 구축을 통해 하드웨어와 소프트웨어 스택을 통합하기 위한 프로비저닝 스케줄러를 구현하였습니다.
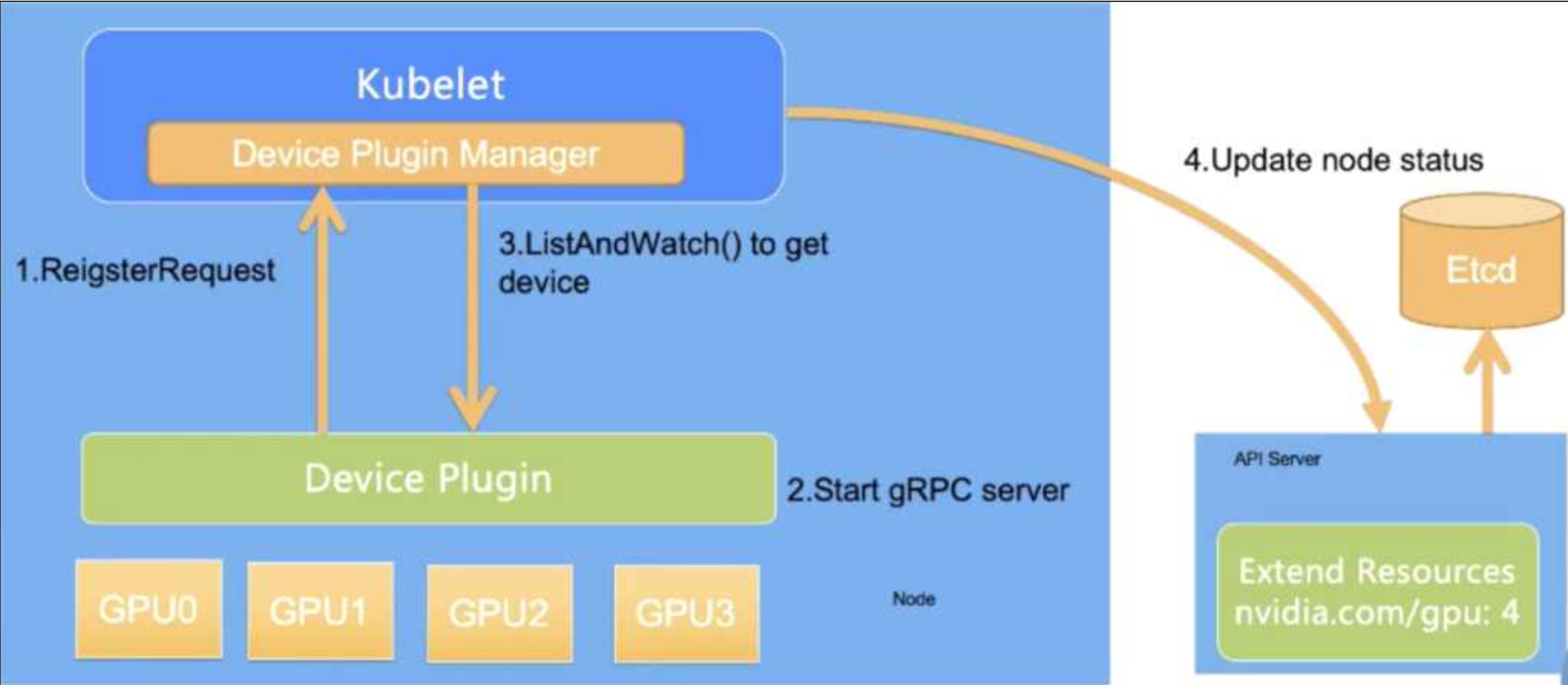
SAPEON Device Plugin
국산 AI 반도체인 사피온(SAPEON)을 클러스터 리소스로 등록하기 위해 전용 Device Plugin을 개발하였습니다. Kubernetes의 ListAndWatch 인터페이스를 gRPC 서버로 구현하여, 커스텀 리소스인 skt.com/aix_v1을 노드의 Capacity에 성공적으로 등록하였습니다.
핵심 구현 코드
Sapeon Device 탐색 코드 보기
// getSapeonDevicesMaps는 시스템에 연결된 모든 SAPEON 장치를 탐색하고
// 모델별로 그룹화하여 Kubernetes Device Plugin 형식으로 반환합니다.
func getSapeonDevicesMaps() map[string][]*pluginapi.Device {
// 사피온 장치 수 파악 및 에러 체크
n, err := sapeon.GetDeviceCount()
check(err)
devsMap := make(map[string][]*pluginapi.Device)
for i := uint(0); i < n; i++ {
d, err := sapeon.NewDevice(i)
check(err)
// 모델명 전처리 (공백을 하이픈으로 대체)
// 예: "AIX V1" -> "AIX-V1"
name := strings.Replace(*d.Model, " ", "-", -1)
devs := append(devsMap[name], &pluginapi.Device{
ID: d.UUID,
Health: pluginapi.Healthy,
})
devsMap[name] = devs
}
return devsMap
}
클러스터에 디바이스 등록 및 프로비저닝 과정
자체 개발한 디바이스 플러그인 데몬셋 구동모습
Triton Inference Server 기반 범용 Backend
NPU 리소스가 프로비저닝된 후에는 실제 모델을 구동할 추론 엔진이 필요합니다. 다양한 하드웨어 백엔드를 통합 관리하기 위해 NVIDIA Triton Inference Server를 포크하여 Custom Backend(libtriton_aix.so) 를 개발하였습니다.
핵심 구현 코드
Sapeon Device 탐색 코드 보기
class ModelInstanceState : public BackendModelInstance {
public:
TRITONSERVER_Error* Execute(
TRITONBACKEND_Request** requests,
const uint32_t request_count
) {
// 배치 입력 수집
std::vector<sapeon_tensor_t> inputs;
for (uint32_t r = 0; r < request_count; ++r) {
TRITONBACKEND_Input* input;
TRITONBACKEND_RequestInput(requests[r], "input", &input);
const void* input_buffer;
uint64_t buffer_byte_size;
TRITONBACKEND_InputBuffer(
input, 0, &input_buffer, &buffer_byte_size
);
inputs.push_back({
.data = input_buffer,
.size = buffer_byte_size
});
}
// SAPEON NPU에서 추론 실행
std::vector<sapeon_tensor_t> outputs;
SAPEON_CHECK(sapeon_execute(
model_state_->sapeon_context_,
model_state_->model_handle_,
inputs.data(), inputs.size(),
outputs.data(), &outputs_count
));
// 결과 반환
for (uint32_t r = 0; r < request_count; ++r) {
TRITONBACKEND_Response* response;
TRITONBACKEND_ResponseNew(&response, requests[r]);
TRITONBACKEND_Output* output;
TRITONBACKEND_ResponseOutput(
response, &output, "output",
TRITONSERVER_TYPE_FP32,
output_shape.data(), output_shape.size()
);
void* output_buffer;
TRITONBACKEND_OutputBuffer(
output, &output_buffer,
outputs[r].size,
&memory_type, &memory_type_id
);
memcpy(output_buffer, outputs[r].data, outputs[r].size);
TRITONBACKEND_ResponseSend(
response,
TRITONSERVER_RESPONSE_COMPLETE_FINAL,
nullptr
);
}
return nullptr;
}
};
SAPEON 용 Custom Backend 구성 목록
이를 통해 하드웨어의 종류에 관계없이 통일된 gRPC/HTTP API 인터페이스를 통해 추론 서비스를 사용자에게 제공할 수 있습니다.
4. 엣지 자원 효율을 위한 추론 파이프라인 최적화
엣지 환경에서 AI 모델을 운영할 때 가장 큰 과제는 한정된 리소스로 복잡한 태스크를 실시간으로 처리하는 것입니다.
단일 영상 스트림에서 여러 모델을 동시에 구동하는 구조를 설계하고, NPU의 불필요한 연산을 줄이는 전처리 로직을 도입하여 시스템 효율을 개선했습니다.
다중 추론 파이프라인 아키텍처
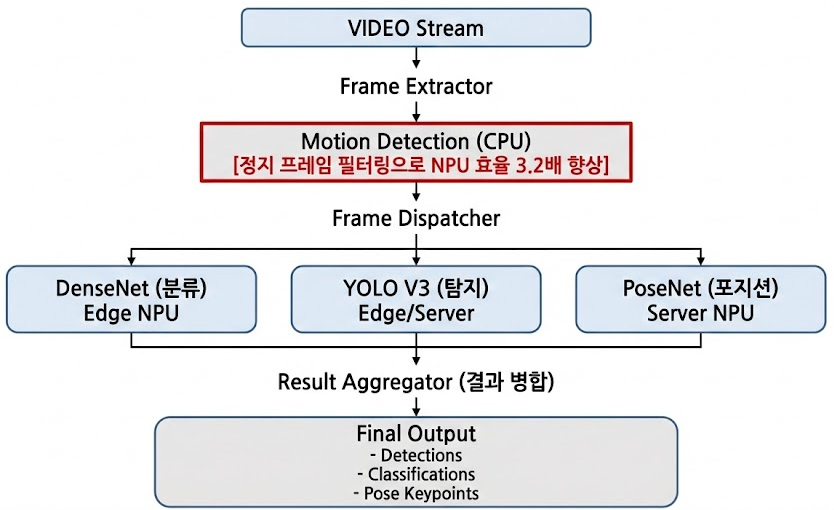
4.1 다중 모델 동시 추론 기술 (Multi-Inference)
실제 서비스 환경에서는 하나의 영상 데이터로부터 객체 탐지, 분류, 포즈 추출 등 다양한 정보를 동시에 얻어야 하는 경우가 많습니다.
본 프로젝트에서는 단일 영상 스트림에 대해 3개 이상의 모델을 병렬로 구동할 수 있는 연합추론을 실증하였습니다.
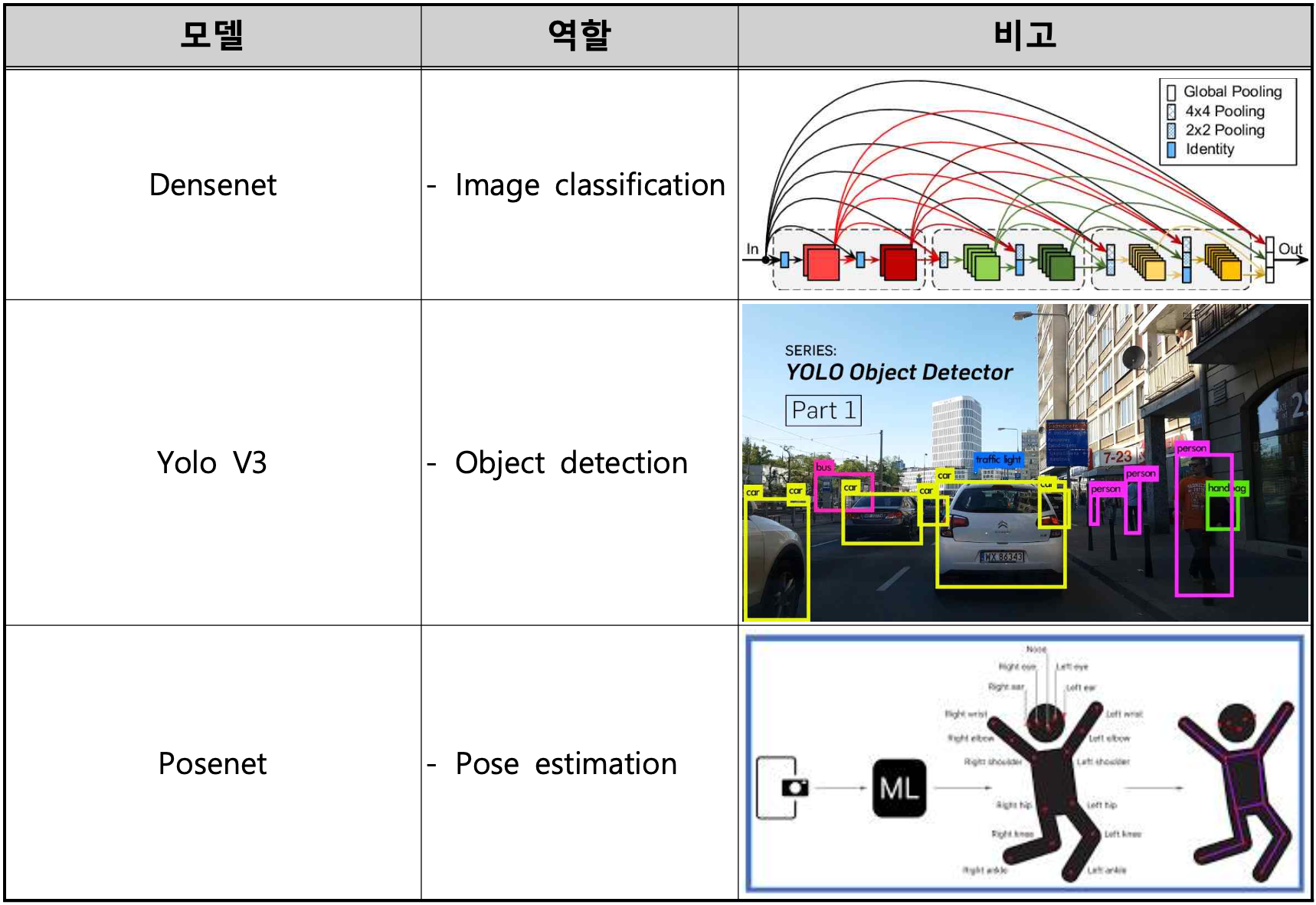
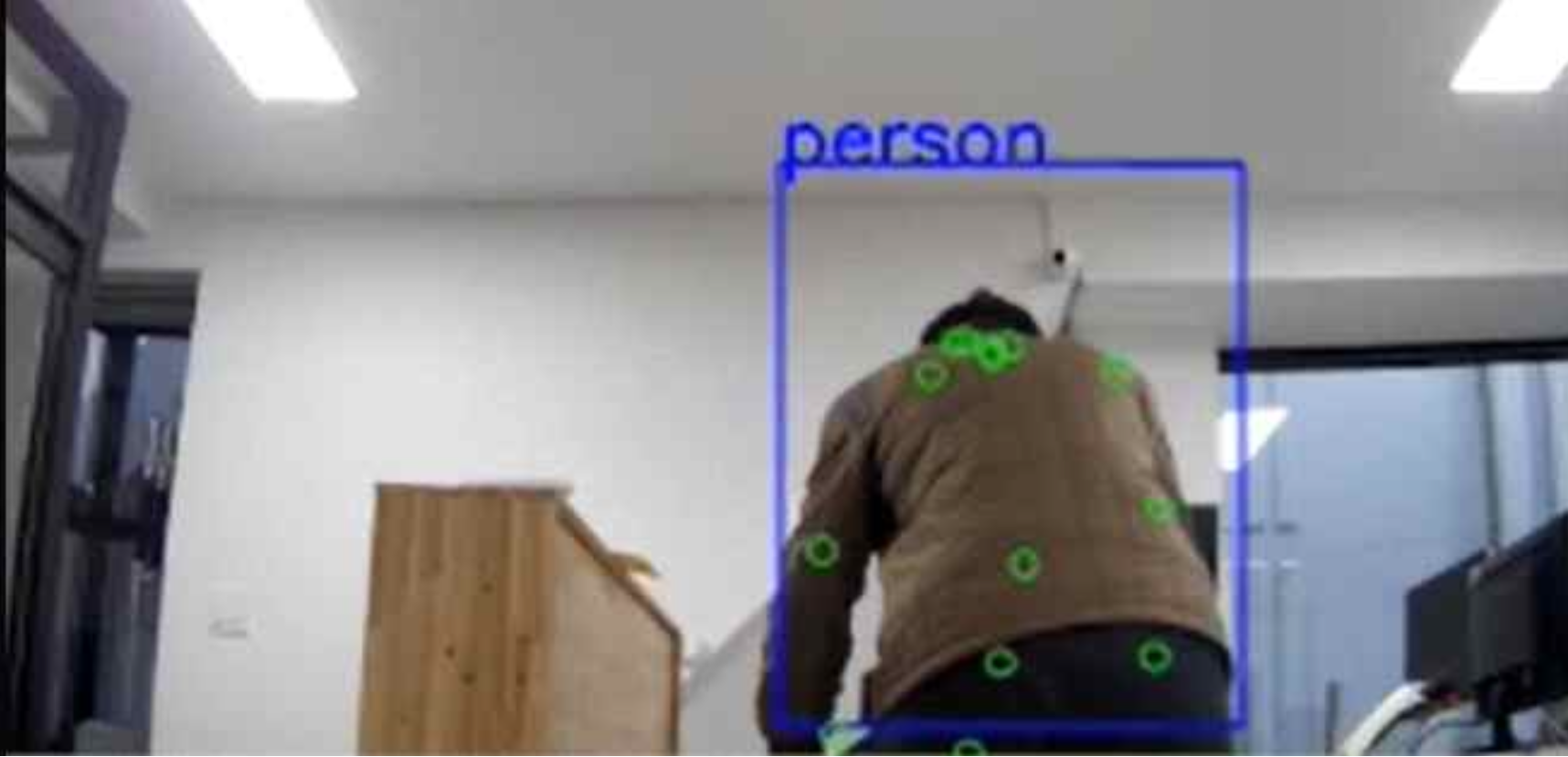
- Densenet 으로 이미지 분류
- Yolo V3로 Object Detection(파란색 박스)
- Posenet으로 Pose estimation(초록색 원)
4.2 CPU 기반 모션 감지(Motion Detection)를 통한 NPU 부하 절감
파이프라인의 전체 효율을 결정짓는 핵심은 NPU가 꼭 필요한 순간에만 작동 하게 만드는 것 입니다.
CCTV와 같은 고정형 카메라 영상은 변화가 없는 정지 구간이 많다는 점에 착안하여, CPU 레벨의 사전 필터링 로직을 도입했습니다.
3-프레임 비교 방식의 원리
단순한 이전 프레임과의 비교는 조명 변화나 노이즈에 취약합니다. 이를 해결하기 위해 연속된 3개의 프레임을 교차 분석하는 방식을 채택했습니다.
시간 축 →
├────────┼────────┼────────┼────────┼────────┤
│Frame A │Frame B │Frame C │Frame D │Frame E │
├────────┼────────┼────────┼────────┼────────┤
비교 방식:
- diff1 = |A - B| (이전 변화)
- diff2 = |B - C| (현재 변화)
- motion = diff1 AND diff2 (지속적인 움직임만 감지)
장점:
- 단순 노이즈(조명 깜빡임 등) 필터링
- 실제 움직이는 객체만 정확히 감지
- CPU만 사용하여 NPU 리소스 절약
이 방식은 일시적인 노이즈를 효과적으로 필터링하며, 실제 움직이는 객체가 존재할 때만 NPU 추론 큐에 프레임을 전달합니다.
핵심 구현 코드
추론 필요성 여부 필터링 코드 보기
def find_motion_detection(q: queue.Queue):
thresh = 25
max_diff = 5
a, b, c = None, None, None
cap = cv2.VideoCapture(VIDEO_INDEX)
ret, a = cap.read()
ret, b = cap.read()
cap.release()
sleep(3)
while True:
cap = cv2.VideoCapture(VIDEO_INDEX)
ret, c = cap.read()
if not ret:
break
cap = cv2.VideoCapture(VIDEO_INDEX)
a_gray = cv2.cvtColor(a, cv2.COLOR_BGR2GRAY)
b_gray = cv2.cvtColor(b, cv2.COLOR_BGR2GRAY)
c_gray = cv2.cvtColor(c, cv2.COLOR_BGR2GRAY)
diff1 = cv2.absdiff(a_gray, b_gray)
diff2 = cv2.absdiff(b_gray, c_gray)
ret, diff1_t = cv2.threshold(diff1, thresh, 255, cv2.THRESH_BINARY)
ret, diff2_t = cv2.threshold(diff2, thresh, 255, cv2.THRESH_BINARY)
diff = cv2.bitwise_and(diff1_t, diff2_t)
# 이미지 잡음 제거
k = cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3))
diff = cv2.morphologyEx(diff, cv2.MORPH_OPEN, k)
diff_cnt = cv2.countNonZero(diff)
if diff_cnt > max_diff: # motion detected!
if not q.full():
_, encoded = cv2.imencode(".jpg", c)
q.put(encoded)
a = b
b = c
5. 성능 벤치마크
5.1 테스트 환경
| 항목 | Edge Cluster | Server Cluster |
|---|---|---|
| NPU | SAPEON X220 × 2 | SAPEON X220 × 8 |
| Network | 5G (평균 67.7ms) | 10GbE Internal |
| OS | Ubuntu 22.04 LTS | Ubuntu 22.04 LTS |
| Orchestrator | KubeEdge 1.15.0 | Kubernetes 1.28.0 |
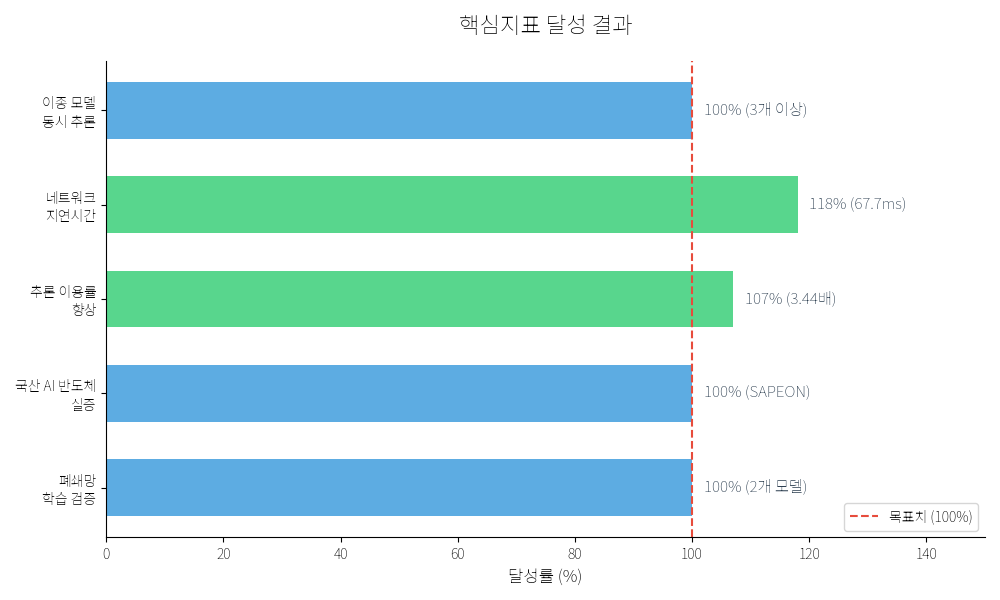
5.2 핵심 지표 달성 결과
- WebRTC를 통한 실시간 스트리밍 및 다중 객체 탐지 기능 검증 완료
| 평가지표 | 목표치 | 최종 달성치 | 달성률 | 기술적 의의 |
|---|---|---|---|---|
| 이종 모델 동시 추론 | 3개 이상 | 달성 | 100% | DenseNet, YOLO V3, PoseNet 동시 구동 |
| 네트워크 지연시간 | 80ms 이내 | 67.7ms | 118% | 5G 및 엣지 클러스터 최적화 결과 |
| 추론 이용률 향상 | 3배 이상 | 3.44배 | 107% | 모션 감지 필터링을 통한 NPU 점유 최적화 |
| 국산 AI 반도체 실증 | 1개 이상 | 달성 | 100% | 사피온(SAPEON) NPU 인터페이스 통합 성공 |
| 폐쇄망 학습 검증 | 2개 모델 | 달성 | 100% | DenseNet, YOLO V3 레퍼런스 모델 학습 성공 |
6. 마무리
본 프로젝트를 통해 국산 NPU(SAPEON) 기반의 Edge AI 인프라부터 최적화된 추론 파이프라인, 그리고 보안 학습 체계까지 아우르는 통합 프레임워크를 성공적으로 실증했습니다.
핵심 성과
- 하드웨어 최적화: SAPEON 전용 Device Plugin 및 Triton Custom Backend 개발을 통한 HW-SW 통합 스택 구축
- 추론 효율 향상: 3-프레임 모션 감지 필터링 도입으로 NPU 연산 효율 3.44배 향상 (목표 대비 107% 달성)
- 네트워크 지연 개선: 5G 및 엣지 클러스터 최적화로 67.7ms의 저지연성 확보 (목표 대비 118% 달성)
- 데이터 보안: 원본 데이터 전송 없는 연합 학습(Federated Learning) 및 암호화 전송 체계 검증
시사점
하드웨어 리소스가 제한적인 엣지 환경일지라도, 하드웨어 특성을 반영한 로우레벨 설계와 지능형 전처리 로직이 뒷받침된다면 클라우드 의존도를 낮춘 고성능 AI 서비스가 충분히 가능함을 확인했습니다.
향후 서비스의 안정적인 AI 기능을 구현하는 핵심 기술 자산으로 활용될 예정입니다.
하드웨어와 소프트웨어의 경계를 넘나드는 최적화를 통해, 사용자에게 더 빠르고 안전한 AI 경험을 제공할 수 있도록 기술 스택을 지속적으로 고도화해 나갈 예정입니다.